
Makine öğreniminde rastgele ormanlar: ne ve nasıl çalıştıkları
Yayınlanan: 2025-02-03Rastgele ormanlar makine öğrenmesinde (ML) güçlü ve çok yönlü bir tekniktir. Bu rehber, rastgele ormanları, nasıl çalıştıklarını ve uygulamalarını, faydalarını ve zorluklarını anlamanıza yardımcı olacaktır.
İçindekiler
- Rastgele orman nedir?
- Karar ağaçları ve rastgele orman: fark nedir?
- Rastgele Ormanlar Nasıl Çalışır?
- Rastgele ormanların pratik uygulamaları
- Rastgele ormanların avantajları
- Rastgele ormanların dezavantajları
Rastgele orman nedir?
Rastgele bir orman, tahmin yapmak için birden fazla karar ağacı kullanan bir makine öğrenme algoritmasıdır. Hem sınıflandırma hem de regresyon görevleri için tasarlanmış denetimli bir öğrenme yöntemidir. Birçok ağacın çıktılarını birleştirerek, rastgele bir orman doğruluğu artırır, aşırı uyumu azaltır ve tek bir karar ağacına kıyasla daha kararlı tahminler sağlar.
Karar ağaçları ve rastgele orman: fark nedir?
Rastgele ormanlar karar ağaçları üzerine inşa edilmiş olsa da, iki algoritma yapı ve uygulamada önemli ölçüde farklılık gösterir:
Karar ağaçları
Bir karar ağacı üç ana bileşenden oluşur: bir kök düğümü, karar düğümleri (dahili düğümler) ve yaprak düğümleri. Bir akış şeması gibi, karar süreci kök düğümünde başlar, koşullara dayalı karar düğümlerinden akar ve sonucu temsil eden bir yaprak düğümünde sona erer. Karar ağaçlarının yorumlanması ve kavramsallaştırılması kolay olsa da, özellikle karmaşık veya gürültülü veri kümeleriyle aşırı takılmaya eğilimlidirler.
Rastgele ormanlar
Rastgele bir orman, geliştirilmiş tahminler için çıktılarını birleştiren bir karar ağaçları topluluğudur. Her ağaç benzersiz bir bootstrap örneğinde (orijinal veri kümesinin rastgele örneklenmiş bir alt kümesi) eğitilir ve her bir düğümde rastgele seçilmiş bir özellik alt kümesini kullanarak karar bölünmelerini değerlendirir. Özellik torbası olarak bilinen bu yaklaşım, ağaçlar arasında çeşitlilik getirir. Regresyon için sınıflandırma veya ortalamalar için çoğunluk oylamasını kullanarak tahminleri toplayarak, regresyon ormanları, topluluktaki herhangi bir karar ağacından daha doğru ve istikrarlı sonuçlar üretir.
Rastgele Ormanlar Nasıl Çalışır?
Rastgele ormanlar, sağlam ve doğru bir tahmin modeli oluşturmak için birden fazla karar ağacını birleştirerek çalışır.
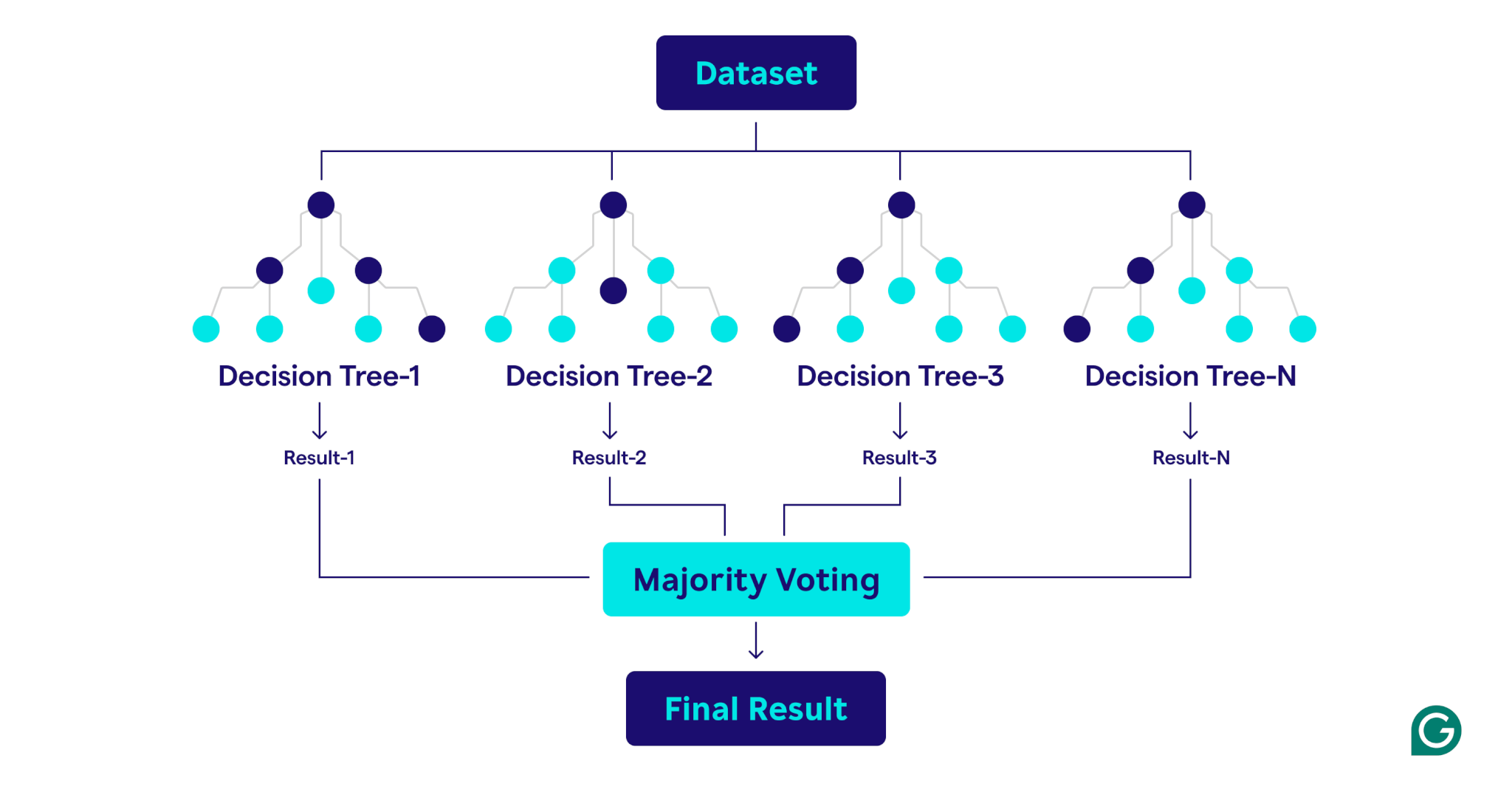
İşte sürecin adım adım bir açıklaması:
1. Hiperparametreleri ayarlama
İlk adım, modelin hiperparametrelerini tanımlamaktır. Bunlar şunları içerir:
- Ağaç Sayısı:Ormanın büyüklüğünü belirler
- Her ağaç için maksimum derinlik:her karar ağacının ne kadar derin büyüyebileceğini kontrol eder
- Her bir bölünmede dikkate alınan özellik sayısı:bölünmeler oluştururken değerlendirilen özellik sayısını sınırlar
Bu hiperparametreler, modelin karmaşıklığını ince ayarlamaya ve belirli veri kümeleri için performansı optimize etmeye izin verir.
2. Bootstrap örneklemesi
Hiperparametreler ayarlandıktan sonra, eğitim süreci bootstrap örneklemesi ile başlar. Bu şunları içerir:
- Orijinal veri kümesinden veri noktaları, her karar ağacı için eğitim veri kümeleri (bootstrap örnekleri) oluşturmak üzere rastgele seçilir.
- Her bootstrap örneği tipik olarak orijinal veri kümesinin büyüklüğünde yaklaşık üçte ikisidir, bazı veri noktaları tekrarlanır ve diğerleri hariç tutulur.
- Bootstrap örneğine dahil olmayan veri noktalarının geri kalan üçte biri, çantalı (OOB) verileri olarak adlandırılır.
3. Karar ağaçları inşa etmek
Rastgele ormandaki her karar ağacı, benzersiz bir işlem kullanılarak karşılık gelen bootstrap örneği üzerinde eğitilir:
- Özellik torbası:Her bölünmede, ağaçlar arasında çeşitliliği sağlayan rastgele bir özellik alt kümesi seçilir.
- Düğüm Bölme:Alt kümeden en iyi özellik, düğümü bölmek için kullanılır:
- Sınıflandırma görevleri için, Gini Smations gibi kriterler (rastgele seçilen bir öğenin, düğümdeki sınıf etiketlerinin dağılımına göre rastgele etiketlenmesi durumunda ne kadar sıklıkla sınıflandırılacağının bir ölçüsü), bölünmenin sınıfları ne kadar iyi ayırdığını ölçer.
- Regresyon görevleri için, varyans azaltma gibi teknikler (bir düğümün ne kadar bölünmenin hedef değerlerinin varyansını ne kadar azalttığını ölçen bir yöntem, daha kesin tahminlere yol açar), bölünmenin tahmin hatasını ne kadar azalttığını değerlendirir.
- Ağaç, maksimum derinlik veya düğüm başına minimum veri noktası gibi durma koşullarını karşılayana kadar özyinelemeyle büyür.
4. Performansı Değerlendirme
Her ağaç oluşturulurken, modelin performansı OOB verileri kullanılarak tahmin edilir:
- OOB hata tahmini, ayrı bir doğrulama veri kümesine olan ihtiyacı ortadan kaldırarak model performansının tarafsız bir ölçüsünü sağlar.
- Rastgele orman, tüm ağaçlardan tahminleri toplayarak, bireysel karar ağaçlarına kıyasla gelişmiş doğruluk elde eder ve aşırı sığmayı azaltır.

Rastgele ormanların pratik uygulamaları
Üzerinde inşa edildikleri karar ağaçları gibi, sağlık ve finans gibi çok çeşitli sektörlerde sınıflandırma ve regresyon problemlerine rastgele ormanlar uygulanabilir.
Hasta Koşullarını Sınıflandırma
Sağlık hizmetlerinde rastgele ormanlar, hasta koşullarını tıbbi öykü, demografi ve test sonuçları gibi bilgilere göre sınıflandırmak için kullanılır. Örneğin, bir hastanın diyabet gibi belirli bir durum geliştirip geliştirmediğini tahmin etmek için, her karar ağacı hastayı ilgili verilere dayanarak risk altında veya almaz ve rastgele orman, çoğunluk oylamasına dayanarak nihai belirlemeyi yapar. Bu yaklaşım, rastgele ormanların sağlık hizmetlerinde bulunan karmaşık, zengin özellikli veri kümeleri için özellikle uygun olduğu anlamına gelir.
Kredi Temerrütlerini Tahmin Etme
Bankalar ve büyük finans kurumları, kredi uygunluğunu belirlemek ve riski daha iyi anlamak için rastgele ormanları yaygın olarak kullanırlar. Model, riski belirlemek için gelir ve kredi puanı gibi faktörleri kullanır. Risk sürekli bir sayısal değer olarak ölçüldüğünden, rastgele orman sınıflandırma yerine regresyon gerçekleştirir. Biraz farklı bootstrap örnekleri üzerinde eğitilen her karar ağacı, öngörülen bir risk puanı çıkarır. Daha sonra, rastgele orman tüm bireysel tahminlerin ortalamaları, sağlam, bütünsel bir risk tahmini ile sonuçlanır.
Müşteri Kaybını Tahmin Etme
Pazarlamada, rastgele ormanlar genellikle bir müşterinin bir ürün veya hizmetin kullanımını bırakma olasılığını tahmin etmek için kullanılır. Bu, satın alma sıklığı ve müşteri hizmetleri ile etkileşimler gibi müşteri davranış modellerinin analiz edilmesini içerir. Bu kalıpları belirleyerek, rastgele ormanlar müşterileri ayrılma riski altındaki sınıflandırabilir. Bu anlayışlarla şirketler, sadakat programları veya hedefli promosyonlar sunmak gibi müşterileri korumak için proaktif, veri odaklı adımlar atabilir.
Gayrimenkul fiyatlarını tahmin etmek
Rastgele ormanlar, bir regresyon görevi olan gayrimenkul fiyatlarını tahmin etmek için kullanılabilir. Tahmin etmek için rastgele orman, coğrafi konum, kare görüntüler ve bölgedeki son satışlar gibi faktörleri içeren geçmiş verileri kullanır. Rastgele Orman'ın ortalama süreci, son derece değişken gayrimenkul piyasalarında yararlı olan bireysel bir karar ağacından daha güvenilir ve istikrarlı bir fiyat tahminiyle sonuçlanır.
Rastgele ormanların avantajları
Rastgele ormanlar, doğruluk, sağlamlık, çok yönlülük ve özellik önemini tahmin etme yeteneği gibi çok sayıda avantaj sunar.
Doğruluk ve sağlamlık
Rastgele ormanlar bireysel karar ağaçlarından daha doğru ve sağlamdır. Bu, orijinal veri kümesinin farklı bootstrap örnekleri üzerinde eğitilmiş birden fazla karar ağacının çıktıları birleştirilerek elde edilir. Ortaya çıkan çeşitlilik, rastgele ormanların aşırı takılmaya bireysel karar ağaçlarından daha az eğilimli olduğu anlamına gelir. Bu topluluk yaklaşımı, rastgele ormanların karmaşık veri kümelerinde bile gürültülü verileri ele almada iyi olduğu anlamına gelir.
Çok yönlülük
Üzerinde inşa edildikleri karar ağaçları gibi, rastgele ormanlar da çok yönlüdür. Hem regresyon hem de sınıflandırma görevlerini yerine getirebilirler, bu da onları çok çeşitli problemlere uygulanabilir hale getirebilirler. Rastgele ormanlar da büyük, özellikli özellikli veri kümeleriyle iyi çalışır ve hem sayısal hem de kategorik verileri işleyebilir.
Özellik önemi
Rastgele ormanlar, belirli özelliklerin önemini tahmin etmek için yerleşik bir yeteneğe sahiptir. Eğitim sürecinin bir parçası olarak, rastgele ormanlar, belirli bir özellik kaldırılırsa modelin doğruluğunun ne kadar değiştiğini ölçen bir puan çıkarır. Her özellik için puanların ortalaması alınarak, rastgele ormanlar özellik öneminin ölçülebilir bir ölçüsünü sağlayabilir. Daha sonra daha verimli ağaçlar ve ormanlar oluşturmak için daha az önemli özellikler kaldırılabilir.
Rastgele ormanların dezavantajları
Rastgele ormanlar birçok fayda sunsa da, tek bir karar ağacından daha zor ve eğitimi daha pahalıdır ve tahminleri diğer modellerden daha yavaş çıkarabilirler.
Karmaşıklık
Rastgele ormanlar ve karar ağaçlarının ortak noktası olsa da, rastgele ormanların yorumlanması ve görselleştirilmesi daha zordur. Bu karmaşıklık ortaya çıkar, çünkü rastgele ormanlar yüzlerce veya binlerce karar ağacı kullanır. Model açıklanabilirliği bir gereklilik olduğunda rastgele ormanların “kara kutu” doğası ciddi bir dezavantajdır.
Hesaplama maliyeti
Yüzlerce veya binlerce karar ağacını eğitmek, tek bir karar ağacını eğitmekten çok daha fazla işleme gücü ve bellek gerektirir. Büyük veri kümeleri söz konusu olduğunda, hesaplama maliyeti daha da yüksek olabilir. Bu büyük kaynak gereksinimi daha yüksek parasal maliyet ve daha uzun eğitim sürelerine neden olabilir. Sonuç olarak, hem hesaplama gücünün hem de hafızanın az olduğu Edge Computing gibi senaryolarda rastgele ormanlar pratik olmayabilir. Bununla birlikte, rastgele ormanlar paralelleştirilebilir, bu da hesaplama maliyetini azaltmaya yardımcı olabilir.
Daha yavaş tahmin süresi
Rastgele bir ormanın tahmin süreci, ormandaki her ağacın geçmeyi ve tek bir model kullanmaktan doğal olarak daha yavaş olan çıktılarını bir araya getirmeyi içerir. Bu işlem, özellikle derin ağaçlar içeren büyük ormanlar için lojistik regresyon veya sinir ağları gibi daha basit modellerden daha yavaş tahmin sürelerine neden olabilir. Yüksek frekanslı ticaret veya otonom araçlar gibi zamanın özü olduğu durumlarda, bu gecikme engelleyici olabilir.