
卷积神经网络基础知识:您需要了解的内容
已发表: 2024-09-10卷积神经网络 (CNN) 是数据分析和机器学习 (ML) 的基本工具。本指南解释了 CNN 的工作原理、它们与其他神经网络的区别、它们的应用以及与其使用相关的优缺点。
目录
- 什么是CNN?
- CNN 的工作原理
- CNN 与 RNN 和 Transformer
- CNN 的应用
- 优点
- 缺点
什么是卷积神经网络?
卷积神经网络 (CNN) 是深度学习不可或缺的神经网络,旨在处理和分析空间数据。它采用带有滤波器的卷积层来自动检测和学习输入中的重要特征,使其对于图像和视频识别等任务特别有效。
让我们稍微解释一下这个定义。空间数据是各部分通过其位置相互关联的数据。图像就是最好的例子。
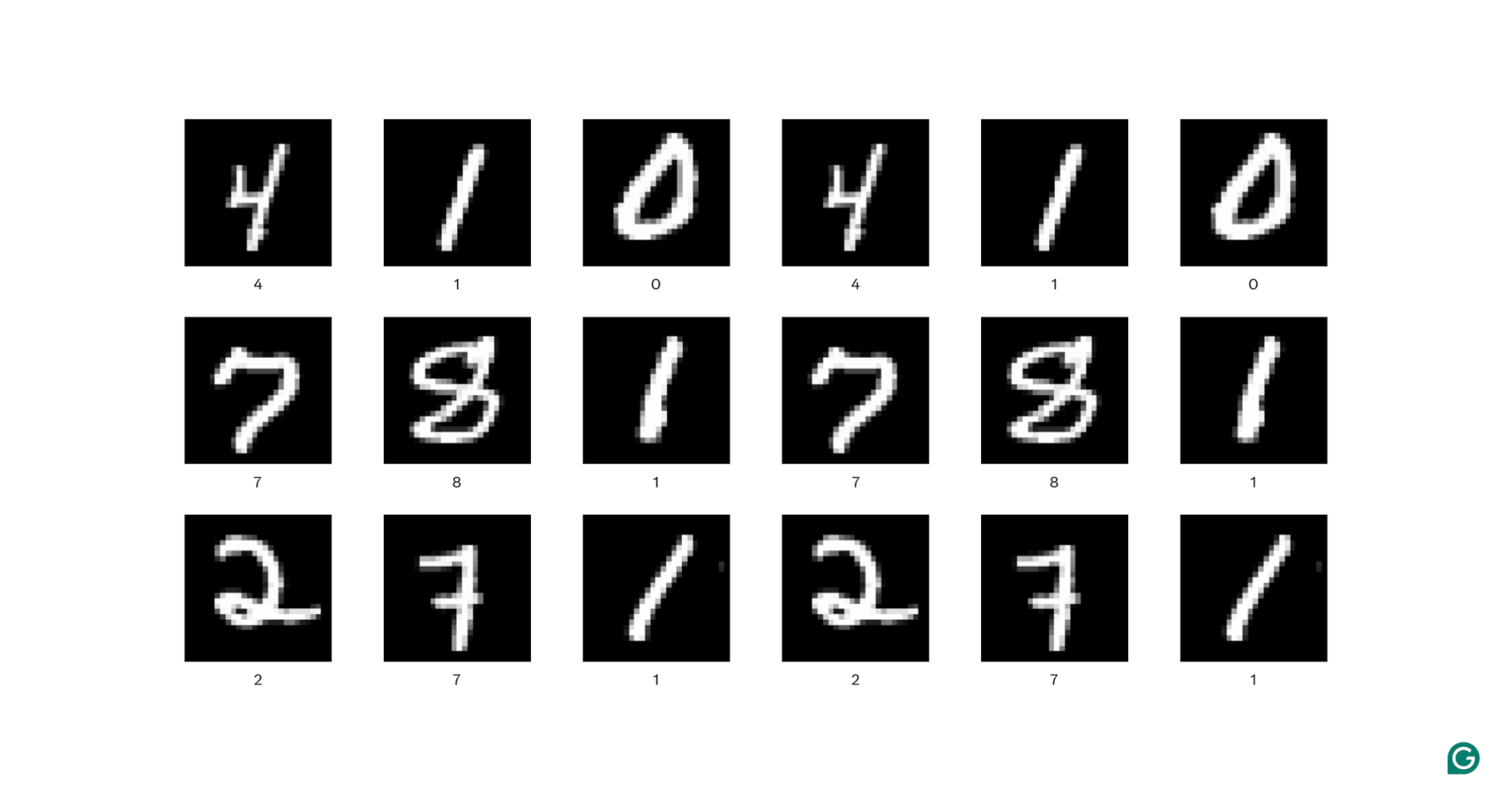
在上面的每个图像中,每个白色像素都连接到每个周围的白色像素:它们形成数字。像素位置还告诉观看者该数字位于图像中的位置。

特征是图像中存在的属性。这些属性可以是任何东西,从稍微倾斜的边缘到鼻子或眼睛的存在,再到眼睛、嘴巴和鼻子的组合。至关重要的是,特征可以由更简单的特征组成(例如,眼睛由一些弯曲边缘和中心黑点组成)。
过滤器是模型的一部分,用于检测图像中的这些特征。每个过滤器都会在整个图像中寻找一个特定特征(例如,从左到右弯曲的边缘)。
最后,卷积神经网络中的“卷积”是指如何将滤波器应用于图像。我们将在下一节中解释这一点。
CNN 在各种图像任务(例如对象检测和图像分割)上表现出了强大的性能。 CNN 模型 (AlexNet) 在 2012 年深度学习的兴起中发挥了重要作用。
CNN 的工作原理
让我们通过确定图像中的数字 (0–9) 来探索 CNN 的整体架构。
在将图像输入模型之前,必须将图像转换为数字表示(或编码)。对于黑白图像,每个像素都会分配一个数字:如果全白则为 255,如果全黑则为 0(有时标准化为 1 和 0)。对于彩色图像,每个像素都分配有三个数字:一个数字表示它包含多少红色、绿色和蓝色,称为 RGB 值。因此,256×256 像素(包含 65,536 像素)的图像在其黑白编码中将具有 65,536 个值,在其彩色编码中将具有 196,608 个值。
然后,模型通过三种类型的层处理图像:
1卷积层:该层对其输入应用过滤器。每个过滤器都是具有定义大小(例如,3×3)的数字网格。该网格从左上角开始覆盖在图像上;将使用第 1-3 列中第 1-3 行的像素值。这些像素值乘以滤波器中的值,然后求和。然后将该总和放入滤波器输出网格的第 1 行第 1 列中。然后滤波器向右滑动一个像素并重复该过程,直到覆盖图像中的所有行和列。通过一次滑动一个像素,滤波器可以找到图像中任何位置的特征,这种特性称为平移不变性。每个过滤器都会创建自己的输出网格,然后将其发送到下一层。
2池化层:该层总结了来自卷积层的特征信息。卷积层返回的输出大于其输入(每个滤波器返回与输入大小大致相同的特征图,并且有多个滤波器)。池化层获取每个特征图并对其应用另一个网格。该网格取其中值的平均值或最大值并输出。然而,这个网格并不是一次移动一个像素;而是一次移动一个像素。它将跳到下一个像素块。例如,3×3 池化网格将首先处理第 1-3 行和第 1-3 列中的像素。然后,它将保留在同一行,但移动到第 4-6 列。在覆盖第一组行 (1-3) 中的所有列后,它将向下移动到第 4-6 行并处理这些列。这有效地减少了输出中的行数和列数。池化层有助于降低复杂性,使模型对噪声和微小变化更加鲁棒,并帮助模型专注于最重要的特征。
3全连接层:经过多轮卷积和池化层之后,最终的特征图被传递到全连接神经网络层,该层返回我们关心的输出(例如,图像是特定数字的概率)。特征图必须被展平(特征图的每一行连接成一个长行),然后组合(每个长特征图行连接成一个巨型行)。

以下是 CNN 架构的直观表示,说明了每一层如何处理输入图像并为最终输出做出贡献:

关于该过程的一些附加说明:
- 每个连续的卷积层都会找到更高级别的特征。第一个卷积层检测边缘、斑点或简单图案。下一个卷积层将第一个卷积层的池化输出作为输入,使其能够检测形成高级特征(例如鼻子或眼睛)的较低级特征的组合。
- 该模型需要训练。在训练期间,图像通过所有层(首先具有随机权重),并生成输出。输出和实际答案之间的差异用于稍微调整权重,使模型将来更有可能正确回答。这是通过梯度下降来完成的,其中训练算法计算每个模型权重对最终答案的贡献程度(使用偏导数),并将其稍微向正确答案的方向移动。池化层没有任何权重,因此不受训练过程的影响。
- CNN 只能处理与训练时大小相同的图像。如果模型在 256×256 像素的图像上进行训练,则任何较大的图像都需要下采样,任何较小的图像都需要上采样。
CNN 与 RNN 和 Transformer
卷积神经网络经常与循环神经网络(RNN)和 Transformer 一起被提及。那么它们有何不同呢?
CNN 与 RNN
RNN 和 CNN 在不同的领域中运行。 RNN 最适合序列数据(例如文本),而 CNN 则擅长处理空间数据(例如图像)。 RNN 有一个内存模块,可以跟踪输入中之前看到的部分,以便将下一部分置于上下文中。相比之下,CNN 通过查看其直接邻居来将部分输入置于上下文中。由于 CNN 缺乏记忆模块,因此它们不太适合文本任务:当它们到达最后一个单词时,它们会忘记句子中的第一个单词。
CNN 与 Transformer
Transformer 也大量用于顺序任务。它们可以使用输入的任何部分来将新输入置于上下文中,这使得它们在自然语言处理 (NLP) 任务中很受欢迎。然而,变压器最近也以视觉变压器的形式应用于图像。这些模型接收图像,将其分解为补丁,对补丁运行注意力(Transformer 架构中的核心机制),然后对图像进行分类。视觉 Transformer 在大型数据集上的表现可以优于 CNN,但它们缺乏 CNN 固有的平移不变性。 CNN 的平移不变性使模型能够识别对象,无论其在图像中的位置如何,这使得 CNN 对于特征的空间关系很重要的任务非常有效。
CNN 的应用
由于 CNN 具有平移不变性和空间特征,因此经常与图像一起使用。但是,通过巧妙的处理,CNN 可以在其他领域工作(通常首先将它们转换为图像)。
图像分类
图像分类是 CNN 的主要用途。训练有素的大型 CNN 可以识别数百万个不同的物体,并且可以处理几乎任何给定的图像。尽管 Transformer 兴起,但 CNN 的计算效率使其成为一种可行的选择。
语音识别
录制的音频可以通过频谱图转换为空间数据,频谱图是音频的视觉表示。 CNN 可以将频谱图作为输入,并学习将不同的波形映射到不同的单词。同样,CNN 可以识别音乐节拍和样本。
图像分割
图像分割涉及识别和绘制图像中不同对象周围的边界。 CNN 在这项任务中很受欢迎,因为它们在识别各种物体方面具有强大的性能。一旦图像被分割,我们就可以更好地理解它的内容。例如,另一个深度学习模型可以分析这些片段并描述这个场景:“两个人在公园里散步。他们的右边有一根灯柱,前面有一辆车。”在医学领域,图像分割可以在扫描中区分肿瘤和正常细胞。对于自动驾驶车辆,它可以识别车道标记、路标和其他车辆。
CNN 的优点
CNN 在业界得到广泛使用有几个原因。
图像表现力强
由于可用的图像数据丰富,因此需要在各种类型的图像上表现良好的模型。 CNN 非常适合此目的。它们的平移不变性以及从较小特征创建较大特征的能力使它们能够检测整个图像的特征。不同类型的图像不需要不同的架构,因为基本的 CNN 可以应用于所有类型的图像数据。
无需手动特征工程
在 CNN 出现之前,性能最好的图像模型需要大量的手动工作。领域专家必须创建模块来检测特定类型的特征(例如,边缘过滤器),这是一个耗时的过程,缺乏针对不同图像的灵活性。每组图像都需要自己的功能集。相比之下,第一个著名的 CNN(AlexNet)可以自动对 20,000 种图像进行分类,减少了手动特征工程的需要。
CNN 的缺点
当然,使用 CNN 需要权衡。
许多超参数
训练 CNN 涉及选择许多超参数。与任何神经网络一样,也存在超参数,例如层数、批量大小和学习率。此外,每个过滤器都需要自己的一组超参数:过滤器大小(例如,3×3、5×5)和步幅(每个步骤后要移动的像素数)。在训练过程中无法轻松调整超参数。相反,您需要使用不同的超参数集(例如,集 A 和集 B)训练多个模型,并比较它们的性能以确定最佳选择。
对输入大小的敏感性
每个 CNN 都经过训练以接受特定尺寸(例如 256×256 像素)的图像。您要处理的许多图像可能与此尺寸不匹配。为了解决这个问题,您可以放大或缩小图像。然而,这种大小调整可能会导致有价值的信息丢失,并可能降低模型的性能。