
生成对抗网络基础知识:您需要了解的内容
已发表: 2024-10-08生成对抗网络 (GAN) 是一种强大的人工智能 (AI) 工具,在机器学习 (ML) 领域有着广泛的应用。本指南探讨了 GAN、它们的工作原理、应用以及它们的优点和缺点。
目录
- 什么是 GAN?
- GAN 与 CNN
- GAN 的工作原理
- GAN 的类型
- GAN 的应用
- GAN 的优点
- GAN 的缺点
什么是生成对抗网络?
生成对抗网络(GAN)是一种深度学习模型,通常用于无监督机器学习,但也适用于半监督和监督学习。 GAN 用于生成类似于训练数据集的高质量数据。作为生成式人工智能的一个子集,GAN 由两个子模型组成:生成器和判别器。
1生成器:生成器创建合成数据。
2鉴别器:鉴别器评估生成器的输出,区分训练集中的真实数据和生成器创建的合成数据。
这两个模型进行竞争:生成器试图欺骗鉴别器将生成的数据分类为真实数据,而鉴别器则不断提高其检测合成数据的能力。这种对抗过程一直持续到鉴别器无法再区分真实数据和生成数据为止。此时,GAN 能够生成逼真的图像、视频和其他类型的数据。
GAN 与 CNN
GAN 和卷积神经网络 (CNN) 是深度学习中使用的强大神经网络类型,但它们在用例和架构方面存在显着差异。
使用案例
- GAN:专门根据训练数据生成真实的合成数据。这使得 GAN 非常适合图像生成、图像风格迁移和数据增强等任务。 GAN 是无监督的,这意味着它们可以应用于标记数据稀缺或不可用的场景。
- CNN:主要用于结构化数据分类任务,例如情感分析、主题分类和语言翻译。由于其分类能力,CNN 也可以作为 GAN 中良好的判别器。然而,由于 CNN 需要结构化的、人工注释的训练数据,因此它们仅限于监督学习场景。
建筑学
- GAN:由两个模型组成——鉴别器和生成器——参与竞争过程。生成器创建图像,而鉴别器对其进行评估,从而推动生成器随着时间的推移生成越来越逼真的图像。
- CNN:利用卷积层和池化操作从图像中提取和分析特征。这种单模型架构专注于识别数据中的模式和结构。
总体而言,CNN 专注于分析现有的结构化数据,而 GAN 则致力于创建新的、真实的数据。
GAN 的工作原理
从较高层面来看,GAN 的工作原理是让两个神经网络(生成器和鉴别器)相互对抗。 GAN 的两个组件都不需要特定类型的神经网络架构,只要所选架构能够相互补充即可。例如,如果使用 CNN 作为图像生成的判别器,则生成器可能是反卷积神经网络 (deCNN),它反向执行 CNN 过程。每个组件都有不同的目标:
- 生成器:生成高质量的数据,使鉴别器被愚弄,将其分类为真实数据。
- 鉴别器:准确地将给定的数据样本分类为真实的(来自训练数据集)或假的(由生成器生成)。
本次比赛是零和游戏的一种实现,其中对一个模型的奖励也是对另一个模型的惩罚。对于生成器来说,成功欺骗鉴别器会导致模型更新,从而增强其生成真实数据的能力。相反,当鉴别器正确识别假数据时,它会收到提高其检测能力的更新。从数学上讲,判别器的目标是最小化分类误差,而生成器的目标是最大化分类误差。
GAN 训练过程
训练 GAN 需要在多个时期交替使用生成器和判别器。 Epoch 是对整个数据集的完整训练。这个过程一直持续到生成器生成的合成数据在大约 50% 的时间内欺骗了鉴别器。虽然这两个模型都使用类似的算法进行性能评估和改进,但它们的更新是独立发生的。这些更新是使用称为反向传播的方法进行的,该方法测量每个模型的误差并调整参数以提高性能。然后,优化算法独立调整每个模型的参数。
这是 GAN 架构的直观表示,说明了生成器和判别器之间的竞争:
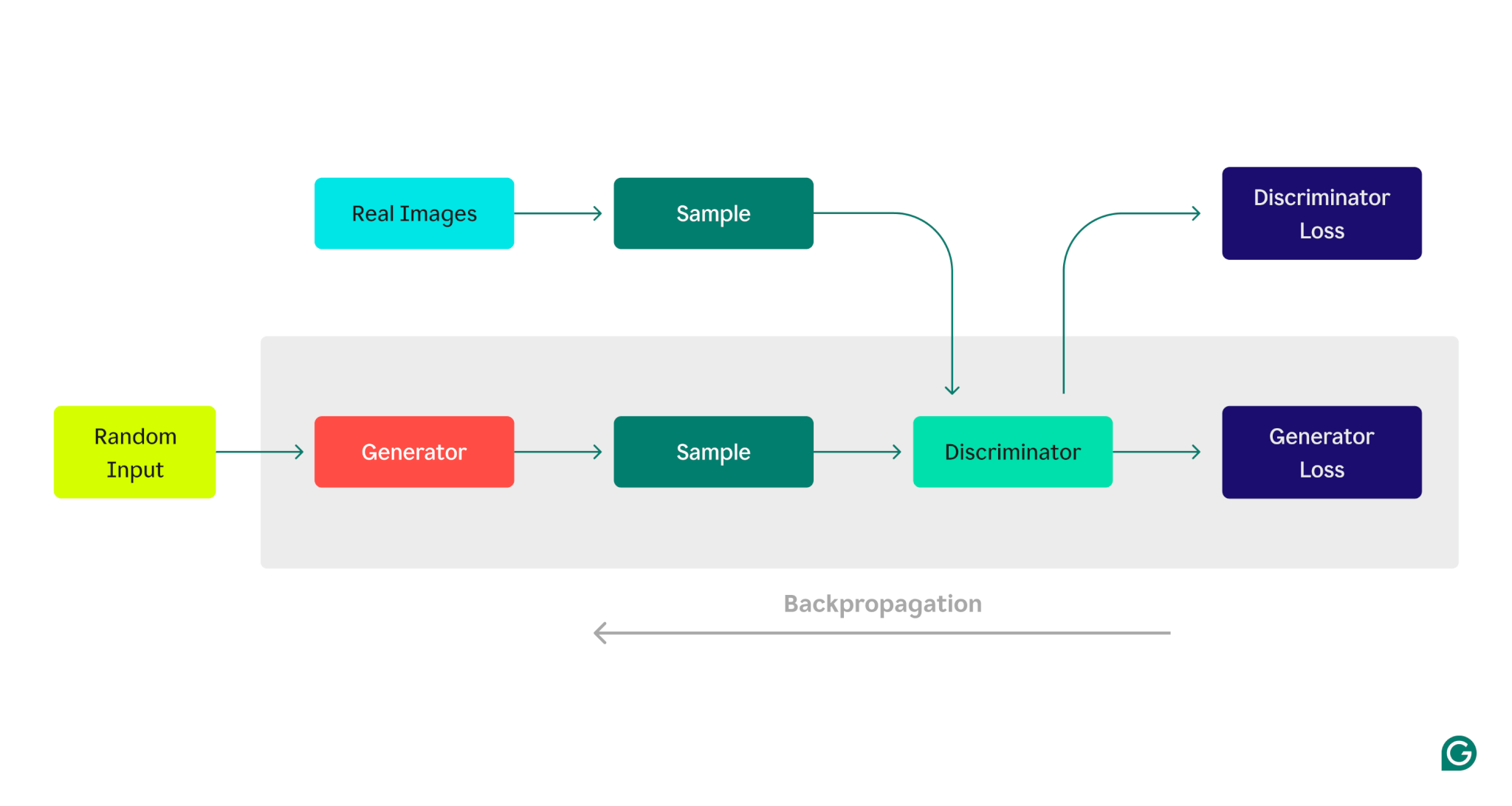
生成器训练阶段:
1生成器创建数据样本,通常以随机噪声作为输入开始。
2鉴别器将这些样本分类为真实样本(来自训练数据集)或假样本(由生成器生成)。
3根据鉴别器的响应,使用反向传播更新生成器参数。

判别器训练阶段:
1使用生成器的当前状态生成虚假数据。
2生成的样本与训练数据集中的样本一起提供给鉴别器。
3使用反向传播,鉴别器的参数根据其分类性能进行更新。
这种迭代训练过程继续进行,每个模型的参数根据其性能进行调整,直到生成器一致地生成鉴别器无法与真实数据可靠区分的数据。
GAN 的类型
在通常称为普通 GAN 的基本 GAN 架构的基础上,还针对各种任务开发和优化了其他专用类型的 GAN。下面描述了一些最常见的变体,但这不是详尽的列表:
条件 GAN (cGAN)
条件 GAN 或 cGAN 使用称为条件的附加信息来指导模型在更通用的数据集上进行训练时生成特定类型的数据。条件可以是类标签、基于文本的描述或数据的其他类型的分类信息。例如,假设您只需要生成暹罗猫的图像,但您的训练数据集包含各种猫的图像。在 cGAN 中,您可以使用猫的类型来标记训练图像,模型可以使用它来学习如何仅生成暹罗猫的图片。
深度卷积 GAN (DCGAN)
深度卷积 GAN(或 DCGAN)针对图像生成进行了优化。在 DCGAN 中,生成器是深度嵌入卷积神经网络 (deCNN),鉴别器是深度 CNN。由于 CNN 能够捕获空间层次结构和模式,因此更适合处理和生成图像。 DCGAN 中的生成器使用上采样和转置卷积层来创建比多层感知器(一种通过权衡输入特征做出决策的简单神经网络)生成的图像质量更高的图像。类似地,鉴别器使用卷积层从图像样本中提取特征,并准确地将其分类为真或假。
循环GAN
CycleGAN 是一种 GAN,旨在从一种类型的图像生成另一种类型的图像。例如,CycleGAN 可以将小鼠的图像转换为大鼠,或将狗的图像转换为土狼。 CycleGAN 能够执行这种图像到图像的转换,而无需对配对数据集(即包含基础图像和所需转换的数据集)进行训练。此功能是通过使用两个生成器和两个鉴别器而不是普通 GAN 使用的一对来实现的。在 CycleGAN 中,一个生成器将图像从基础图像转换为变换后的版本,而另一个生成器则以相反的方向执行转换。同样,每个鉴别器检查特定的图像类型以确定它是真实的还是虚假的。然后,CycleGAN 使用一致性检查来确保将图像转换为其他样式并返回原始图像。
GAN 的应用
由于其独特的架构,GAN 已应用于一系列创新用例,但其性能高度依赖于特定任务和数据质量。一些更强大的应用程序包括文本到图像生成、数据增强以及视频生成和操作。
文本到图像的生成
GAN 可以根据文本描述生成图像。该应用程序在创意产业中很有价值,它允许作者和设计师可视化文本中描述的场景和人物。虽然 GAN 通常用于此类任务,但其他生成式 AI 模型(例如 OpenAI 的 DALL-E)使用基于 Transformer 的架构来实现类似的结果。
数据增强
GAN 对于数据增强很有用,因为它们可以生成类似于真实训练数据的合成数据,尽管准确度和真实度可能会根据具体用例和模型训练而有所不同。此功能在机器学习中对于扩展有限数据集和增强模型性能特别有价值。此外,GAN 还提供了维护数据隐私的解决方案。在医疗保健和金融等敏感领域,GAN 可以生成合成数据,保留原始数据集的统计属性,而不会泄露敏感信息。
视频生成和操作
GAN 在某些视频生成和操作任务中表现出了良好的前景。例如,GAN 可用于从初始视频序列生成未来帧,有助于预测行人运动或预测自动驾驶车辆的道路危险等应用。然而,这些应用仍在积极研究和开发中。 GAN 还可用于生成完全合成的视频内容,并通过逼真的特效增强视频。
GAN 的优点
GAN 具有多种独特的优势,包括生成真实合成数据、从不配对数据中学习以及执行无监督训练的能力。
高质量的合成数据生成
GAN 的架构允许他们生成可以在数据增强和视频创建等应用中近似真实世界数据的合成数据,尽管这些数据的质量和精度在很大程度上取决于训练条件和模型参数。例如,DCGAN 利用 CNN 进行最佳图像处理,擅长生成逼真的图像。
能够从不配对的数据中学习
与某些 ML 模型不同,GAN 可以从数据集中学习,而无需成对的输入和输出示例。这种灵活性使得 GAN 能够广泛应用于配对数据稀缺或不可用的任务中。例如,在图像到图像的翻译任务中,传统模型通常需要图像数据集及其转换来进行训练。相比之下,GAN 可以利用更广泛的潜在数据集进行训练。
无监督学习
GAN 是一种无监督的机器学习方法,这意味着它们可以在没有明确指导的情况下对未标记的数据进行训练。这是特别有利的,因为标记数据是一个耗时且昂贵的过程。 GAN 能够从未标记的数据中学习,这使得它们对于标记数据有限或难以获取的应用很有价值。 GAN 还可以适用于半监督和监督学习,从而允许它们也使用标记数据。
GAN 的缺点
虽然 GAN 是机器学习中的强大工具,但其架构存在一系列独特的缺点。这些缺点包括对超参数的敏感性、高计算成本、收敛失败以及称为模式崩溃的现象。
超参数敏感性
GAN 对超参数很敏感,这些参数是在训练之前设置的,而不是从数据中学习的。示例包括网络架构和单次迭代中使用的训练示例的数量。这些参数的微小变化可能会显着影响训练过程和模型输出,因此需要针对实际应用进行广泛的微调。
计算成本高
由于其复杂的架构、迭代训练过程和超参数敏感性,GAN 通常会产生高昂的计算成本。成功训练 GAN 需要专门且昂贵的硬件以及大量时间,这对于许多希望利用 GAN 的组织来说可能是一个障碍。
收敛失败
工程师和研究人员可以花费大量时间来试验训练配置,然后才能达到模型输出变得稳定和准确的可接受速率(称为收敛速率)。 GAN 中的收敛可能非常难以实现,并且可能不会持续很长时间。收敛失败是指鉴别器无法充分区分真实数据和虚假数据,导致准确度约为 50%,因为它没有获得识别真实数据的能力,这与成功训练期间达到的预期平衡不同。一些 GAN 可能永远无法达到收敛,并且可能需要专门的分析来修复。
模式崩溃
GAN 很容易出现一种称为模式崩溃的问题,即生成器创建的输出范围有限,并且无法反映现实世界数据分布的多样性。这个问题源于 GAN 架构,因为生成器过于专注于生成可以欺骗鉴别器的数据,导致鉴别器生成类似的示例。