
机器学习 101:它是什么以及它如何工作
已发表: 2024-05-23机器学习 (ML) 已迅速成为当今时代最重要的技术之一。 它是 ChatGPT、Netflix 推荐、自动驾驶汽车和电子邮件垃圾邮件过滤器等产品的基础。 为了帮助您了解这种普遍存在的技术,本指南介绍了 ML 是什么(以及不是什么)、它的工作原理及其影响。
目录
- 什么是机器学习?
- 机器学习的工作原理
- 机器学习的类型
- 应用领域
- 优点
- 缺点
- 机器学习的未来
- 结论
什么是机器学习?
要了解机器学习,我们必须首先了解人工智能(AI)。 尽管两者可以互换使用,但它们并不相同。 人工智能既是一个目标,也是一个研究领域。 目标是构建能够在人类(甚至超人)水平上思考和推理的计算机系统。 人工智能还包括许多不同的方法来实现这一目标。 机器学习是这些方法之一,使其成为人工智能的一个子集。
机器学习特别注重使用数据和统计来实现人工智能。 目标是创建智能系统,该系统可以通过输入大量示例(数据)来学习,并且不需要显式编程。 有了足够的数据和良好的学习算法,计算机就能识别数据中的模式并提高其性能。
相比之下,人工智能的非机器学习方法不依赖于数据,并且写入了硬编码逻辑。例如,您可以通过编码所有最佳动作(有255,168 种可能的井字游戏,所以这需要一段时间,但仍然有可能)。 然而,对国际象棋人工智能机器人进行硬编码是不可能的——可能的国际象棋游戏比宇宙中的原子还要多。 在这种情况下,机器学习会发挥更好的作用。
此时一个合理的问题是,当你给出例子时,计算机究竟会如何改进?
机器学习的工作原理
在任何 ML 系统中,您都需要三样东西:数据集、ML 模型(GPT 就是一个例子)和训练算法。 首先,您传入数据集中的示例。 然后,模型会预测该示例的正确输出。 如果模型错误,您可以使用训练算法使模型更有可能适用于将来的类似示例。 您可以重复此过程,直到用完数据或对结果感到满意为止。 完成此过程后,您可以使用模型来预测未来的数据。
此过程的一个基本示例是教计算机识别如下所示的手写数字。
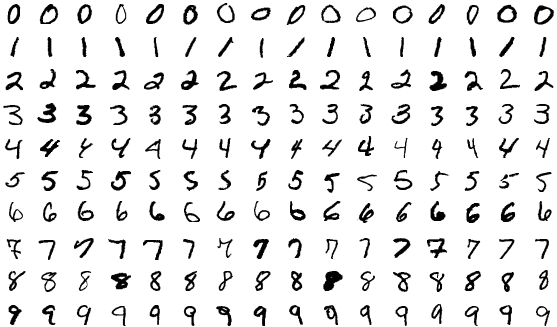
来源
您收集了数千或数十万张数字图片。 您从尚未看到任何示例的 ML 模型开始。 您将图像输入模型并要求它预测图像中的数字。 它将返回 0 到 9 之间的数字,例如 1。 然后,你本质上告诉它,“这个数字实际上是五,而不是一。” 训练算法会更新模型,因此下次更有可能响应 5。 您对(几乎)所有可用图片重复此过程,理想情况下,您拥有一个性能良好的模型,可以在 90% 的时间内正确识别数字。 现在,您可以使用此模型以比人类更快的速度大规模读取数百万位数字。 在实践中,美国邮政服务使用机器学习模型来读取 98% 的手写地址。
您可能会花费数月或数年的时间来剖析此过程的细节,即使是一小部分(看看有多少不同版本的优化算法)。
机器学习的常见类型
实际上有四种不同类型的机器学习方法:监督式、无监督式、半监督式和强化式。 主要区别在于数据的标记方式(即有或没有正确答案)。
监督学习
监督学习模型被赋予标记数据(带有正确答案)。 手写数字的例子就属于这一类:我们可以告诉模型,“五是正确的答案。” 该模型旨在学习输入和输出之间的显式联系。 这些模型可以输出离散标签(例如,根据宠物图像预测“猫”或“狗”)或数字(例如,根据床、浴室、位置等的数量预测房屋的价格) 。
无监督学习
无监督学习模型给出未标记的数据(没有正确答案)。 这些模型识别输入数据中的模式以对数据进行有意义的分组。 例如,给定许多没有正确答案的猫和狗图像,无监督机器学习模型会查看图像中的相似性和差异,以将狗和猫图像分组在一起。 聚类、关联规则和降维是无监督机器学习的核心方法。
半监督学习
半监督学习是一种介于监督学习和无监督学习之间的机器学习方法。 该方法提供了大量的未标记数据和较小的标记数据集来训练模型。 首先,模型在标记数据上进行训练,然后通过比较未标记数据与标记数据的相似度来为未标记数据分配标签。
强化学习
强化学习没有一组给定的示例和标签。 相反,模型被赋予一个环境(例如,游戏是常见的)、奖励函数和目标。 该模型通过反复试验来学习实现目标。 它将执行一项操作,奖励函数会告诉它该操作是否有助于实现总体目标。 然后,模型会更新自身以执行或多或少的该操作。 该模型可以通过多次执行此操作来学习实现目标。
强化学习模型的一个著名例子是 AlphaGo Zero。 该模型经过训练以赢得围棋比赛,并且只给出了围棋棋盘的状态。 然后,它与自己进行了数百万场比赛,随着时间的推移,它学习哪些动作给它带来了优势,哪些动作没有。 它在 70 小时的训练中取得了超人水平的表现,超越了围棋世界冠军。
自我监督学习
实际上,第五种类型的机器学习最近变得很重要:自我监督学习。 自监督学习模型会获得未标记的数据,但会学习根据这些数据创建标签。 这是 ChatGPT 背后的 GPT 模型的基础。 在 GPT 训练期间,模型的目标是在给定输入单词字符串的情况下预测下一个单词。 例如,以“猫坐在垫子上”这句话为例。 GPT 被给予“The”,并被要求预测接下来出现的单词是什么。 它做出预测(例如“狗”),但由于它有原始句子,它知道正确的答案是什么:“猫”。 然后,GPT 被赋予“The cat”并要求预测下一个单词,依此类推。 通过这样做,它可以学习单词之间的统计模式等等。
机器学习的应用
任何拥有大量数据的问题或行业都可以使用机器学习。 许多行业都看到了这样做的非凡成果,并且更多的用例不断出现。 以下是机器学习的一些常见用例:
写作
ML 模型为 Grammarly 等生成式 AI 写作产品提供了动力。 通过接受大量优秀写作的培训,Grammarly 可以为您创建草稿,帮助您重写和润色,并与您一起集思广益,所有这些都以您喜欢的语气和风格进行。

语音识别
Siri、Alexa 和 ChatGPT 的语音版本都依赖于 ML 模型。 这些模型经过许多音频示例以及相应的正确转录本的训练。 通过这些示例,模型可以将语音转换为文本。 如果没有机器学习,这个问题几乎会变得棘手,因为每个人都有不同的说话和发音方式。 不可能列举所有的可能性。
建议
TikTok、Netflix、Instagram 和 Amazon 上的动态背后都是 ML 推荐模型。 这些模型经过许多偏好示例的训练(例如,像您这样的人喜欢这部电影而不是那部电影,喜欢这个产品而不是那个产品),以向您展示您想要查看的项目和内容。 随着时间的推移,这些模型还可以结合您的具体偏好来创建对您特别有吸引力的提要。
欺诈识别
银行使用机器学习模型来检测信用卡欺诈。 电子邮件提供商使用机器学习模型来检测和转移垃圾邮件。 欺诈 ML 模型给出了许多欺诈数据的示例; 然后,这些模型学习数据中的模式,以识别未来的欺诈行为。
自动驾驶汽车
自动驾驶汽车使用机器学习来解释和导航道路。 机器学习帮助汽车识别行人和道路车道,预测其他汽车的运动,并决定他们的下一步行动(例如加速、变换车道等)。 自动驾驶汽车通过使用这些机器学习方法对数十亿个示例进行训练来获得熟练程度。
机器学习的优点
如果做得好,机器学习可以带来变革。 机器学习模型通常可以使流程更便宜、更好或两者兼而有之。
劳动力成本效率
经过训练的机器学习模型可以以一小部分成本模拟专家的工作。 例如,人类专家房地产经纪人对于房屋的价格有很强的直觉,但这可能需要多年的培训。 聘请专业房地产经纪人(以及任何类型的专家)的成本也很高。 然而,经过数百万个示例训练的机器学习模型可能会更接近专业房地产经纪人的表现。 这样的模型可以在几天内完成训练,并且一旦训练完成,使用成本就会低得多。 经验不足的房地产经纪人可以使用这些模型在更短的时间内完成更多的工作。
时间效率
机器学习模型不像人类那样受时间限制。 AlphaGo Zero在三天的训练中下了490 万盘围棋。 人类需要数年甚至数十年才能做到这一点。 由于这种可扩展性,该模型能够探索各种围棋走法和走法,从而实现超人的表现。 机器学习模型甚至可以发现专家错过的模式; AlphaGo Zero 甚至发现并使用了人类通常不会下的棋法。 但这并不意味着专家不再有价值。 通过使用 AlphaGo 等模型来尝试新策略,围棋专家已经进步很多。
机器学习的缺点
当然,使用机器学习模型也有缺点。 也就是说,它们的训练成本很高,而且它们的结果也不容易解释。
培训费用昂贵
机器学习培训可能会变得昂贵。 例如,AlphaGo Zero的开发成本为2500万美元,GPT-4的开发成本超过1亿美元。 开发机器学习模型的主要成本是数据标记、硬件费用和员工工资。
优秀的监督机器学习模型需要数百万个标记示例,每个示例都必须由人类标记。 收集完所有标签后,需要专门的硬件来训练模型。 图形处理单元 (GPU) 和张量处理单元 (TPU) 是 ML 硬件的标准,租用或购买可能会很昂贵 - GPU 的购买成本可能在数千到数万美元之间。
最后,开发优秀的机器学习模型需要聘请机器学习研究人员或工程师,由于他们的技能和专业知识,他们可以要求高薪。
决策的清晰度有限
对于许多机器学习模型来说,尚不清楚它们为何给出这样的结果。 AlphaGo Zero无法解释其决策背后的原因; 它知道某项举措在特定情况下会起作用,但不知道为什么。 当机器学习模型在日常情况下使用时,这可能会产生重大后果。 医疗保健中使用的机器学习模型可能会给出不正确或有偏差的结果,而我们可能不知道这一点,因为其结果背后的原因是不透明的。 一般来说,偏差是机器学习模型的一个巨大问题,而缺乏可解释性使得问题更难解决。 这些问题尤其适用于深度学习模型。 深度学习模型是使用多层神经网络来处理输入的机器学习模型。 他们能够处理更复杂的数据和问题。
另一方面,更简单、更“浅”的机器学习模型(例如决策树和回归模型)不会遇到同样的缺点。 它们仍然需要大量数据,但以其他方式进行训练的成本较低。 它们也更容易解释。 缺点是此类模型的实用性可能受到限制。 GPT 等高级应用程序需要更复杂的模型。
机器学习的未来
基于 Transformer 的 ML 模型在过去几年中风靡一时。 这是为 GPT(GPT 中的 T)、Grammarly 和 Claude AI 提供支持的特定 ML 模型类型。 基于扩散的 ML 模型为 DALL-E 和 Midjourney 等图像创建产品提供支持,也受到了关注。
这种趋势似乎不会很快改变。 机器学习公司专注于增加模型的规模——更大的模型具有更好的功能和更大的数据集来训练它们。 例如,GPT-4 的模型参数数量是 GPT-3 的 10 倍。 我们可能会看到更多行业在其产品中使用生成式人工智能,为用户创造个性化体验。
机器人技术也在升温。 研究人员正在使用机器学习来创建可以像人类一样移动和使用物体的机器人。 这些机器人可以在他们的环境中进行实验,并使用强化学习来快速适应并实现他们的目标,例如,如何踢足球。
然而,随着机器学习模型变得更加强大和普遍,人们担心它们对社会的潜在影响。 偏见、隐私和工作替代等问题正在引起激烈争论,人们越来越认识到道德准则和负责任的开发实践的必要性。
结论
机器学习是人工智能的一个子集,其明确目标是通过让系统从数据中学习来创建智能系统。 监督学习、无监督学习、半监督学习和强化学习(以及自监督学习)是 ML 的主要类型。 ML 是当今推出的许多新产品的核心,例如 ChatGPT、自动驾驶汽车和 Netflix 推荐。 它可能比人类的表现更便宜或更好,但与此同时,它最初的成本很高,而且难以解释和操纵。 机器学习也有望在未来几年变得更加流行。
机器学习有很多复杂之处,学习和为该领域做出贡献的机会正在不断增加。 特别是,Grammarly 关于 AI、深度学习和 ChatGPT 的指南可以帮助您更多地了解该领域的其他重要部分。 除此之外,深入了解 ML 的细节(例如数据如何收集、模型实际是什么样子以及“学习”背后的算法)可以帮助您将其有效地融入到您的工作中。
随着 ML 的不断发展,并且预计它将触及几乎所有行业,现在是开始您的 ML 之旅的时候了!