
机器学习中的随机森林:它们是什么以及它们的工作方式
已发表: 2025-02-03随机森林是机器学习(ML)中一种强大而多功能的技术。本指南将帮助您了解随机森林,它们的工作方式以及其应用,福利和挑战。
目录
- 什么是随机森林?
- 决策树与随机森林:有什么区别?
- 随机森林如何工作
- 随机森林的实际应用
- 随机森林的优势
- 随机森林的缺点
什么是随机森林?
随机森林是一种使用多个决策树来预测的机器学习算法。这是一种专为分类和回归任务而设计的监督学习方法。通过将许多树木的产出结合在一起,随机森林提高了准确性,降低了过度拟合,并且与单个决策树相比提供了更稳定的预测。
决策树与随机森林:有什么区别?
尽管随机森林建立在决策树上,但两种算法在结构和应用方面有显着差异:
决策树
决策树由三个主要组成部分组成:根节点,决策节点(内部节点)和叶节点。与流程图一样,决策过程从根节点开始,根据条件流出决策节点,并以代表结果的叶节点结束。尽管决策树易于解释和概念化,但它们也容易过度拟合,尤其是使用复杂或嘈杂的数据集。
随机森林
随机森林是决策树的合奏,结合了产量以改进预测。每棵树都经过唯一的自举样品(用替换的原始数据集的随机采样子集)进行训练,并使用每个节点处的特征的随机选择子集评估决策拆分。这种称为特征包装的方法引入了树木之间的多样性。通过汇总预测(使用对分类或回归平均值的多数投票),兰多森森林比合奏中的任何单个决策树都会产生更准确和稳定的结果。
随机森林如何工作
随机森林通过组合多个决策树来创建强大而准确的预测模型来运作。
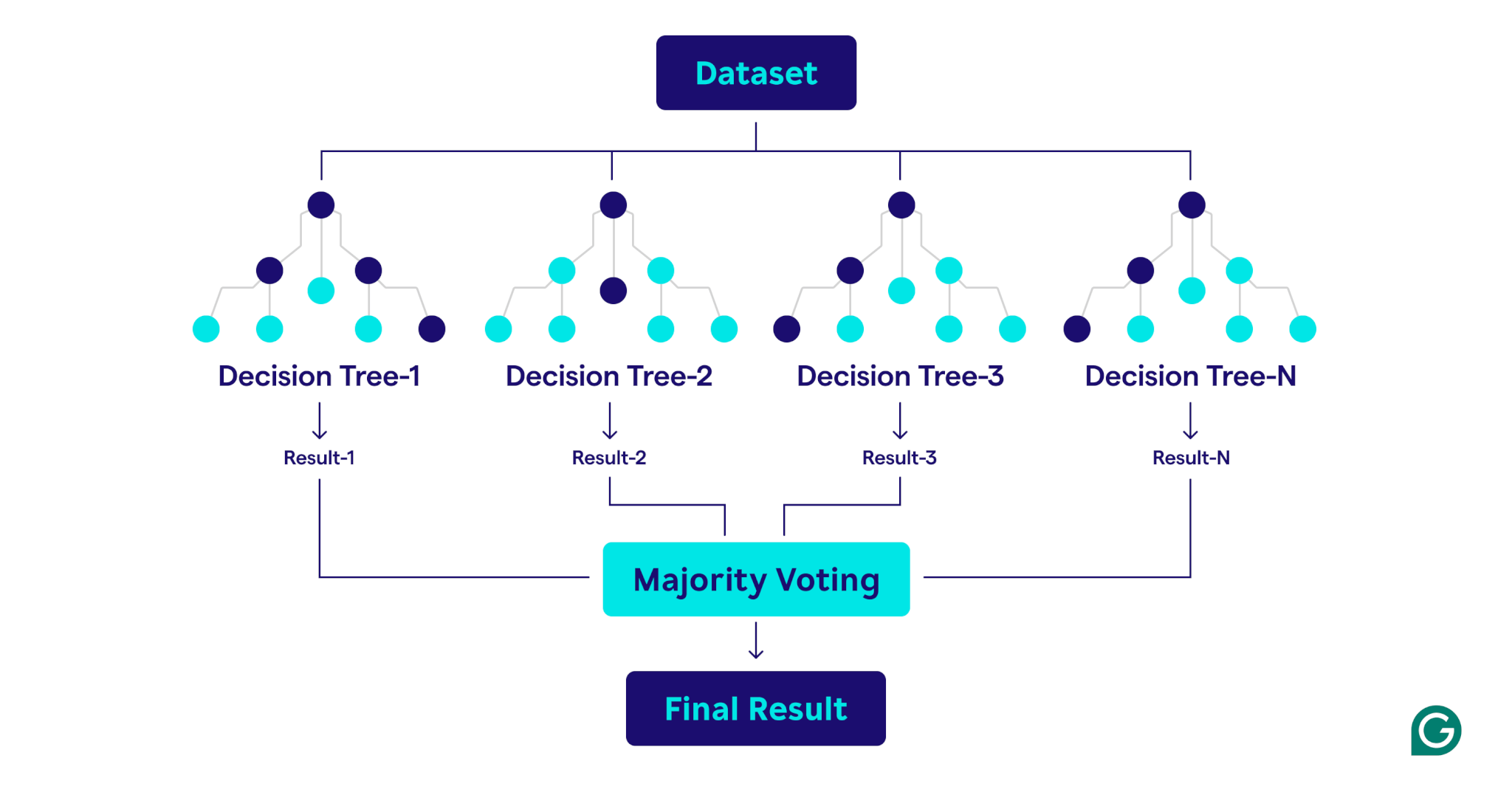
这是该过程的分步说明:
1。设置超参数
第一步是定义模型的超参数。其中包括:
- 树木数:确定森林的大小
- 每棵树的最大深度:控制每个决策树可以生长的深度
- 每次分开考虑的功能数量:限制创建拆分时评估的功能数量
这些超参数允许微调模型的复杂性并优化特定数据集的性能。
2。引导抽样
设置了超参数后,训练过程始于自举抽样。这涉及:
- 随机选择原始数据集中的数据点以为每个决策树创建培训数据集(引导程序样本)。
- 每个引导程序样本通常约为原始数据集的大小的三分之二,有些数据点重复,而另一些数据点则排除在外。
- 其余的三分之一的数据点(未包含在引导程序样本中)被称为外面(OOB)数据。
3。建造决策树
随机森林中的每个决策树都使用唯一过程对其相应的自举样品进行了训练:
- 功能包:在每次分开时,都会选择一个随机的特征子集,从而确保树木之间的多样性。
- 节点拆分:子集中的最佳功能用于拆分节点:
- 对于分类任务,诸如Gini杂质之类的标准(对随机选择的元素的频率度量,如果根据节点中的类标签的分布将其随机标记,则将其分类不正确)。
- 对于回归任务,诸如降低方差之类的技术(一种测量分裂节点的方法降低了目标值的方差,从而导致更精确的预测)评估拆分减少预测误差的程度。
- 该树递归生长,直到达到停止条件,例如最大深度或每个节点的最小数据点。
4。评估性能
在构造每棵树时,使用OOB数据估算模型的性能:

- OOB误差估计提供了对模型性能的公正度量,从而消除了对单独的验证数据集的需求。
- 通过汇总所有树木的预测,与单个决策树相比,随机森林可提高准确性并减少过度拟合。
随机森林的实际应用
像建造的决策树一样,随机森林可以应用于各种各样的部门(例如医疗保健和金融)的分类和回归问题。
分类患者状况
在医疗保健中,随机森林用于根据病史,人口统计和测试结果等信息来对患者条件进行分类。例如,为了预测患者是否可能患有糖尿病等特定疾病,每个决策树都会根据相关数据将患者归类为处于风险中,并且随机森林基于多数投票做出最终确定。这种方法意味着随机森林特别适合医疗保健中发现的复杂,功能丰富的数据集。
预测贷款违约
银行和主要金融机构广泛使用随机森林来确定贷款资格并更好地了解风险。该模型使用收入和信用评分等因素来确定风险。由于风险被衡量为连续数值,因此随机森林执行回归而不是分类。在略有不同的引导样品样本上训练的每个决策树都会输出预测的风险评分。然后,随机森林平均所有个体预测,从而产生了强大的整体风险估计。
预测客户损失
在营销中,随机森林通常用于预测客户停止使用产品或服务的可能性。这涉及分析客户行为模式,例如购买频率和与客户服务的互动。通过识别这些模式,随机森林可以对有离开风险的客户进行分类。有了这些见解,公司可以采取积极主动的数据驱动步骤来保留客户,例如提供忠诚度计划或有针对性的促销。
预测房地产价格
随机森林可用于预测房地产价格,这是一项回归任务。为了进行预测,随机森林使用历史数据,其中包括地理位置,平方英尺和该地区最近销售的因素。随机森林的平均过程比单个决策树的价格预测更可靠,更稳定,这在高度波动的房地产市场中很有用。
随机森林的优势
随机森林提供了许多优势,包括准确性,鲁棒性,多功能性以及估计特征重要性的能力。
准确性和鲁棒性
随机森林比单个决策树更准确,更健壮。这是通过结合在原始数据集的不同引导样本上训练的多个决策树的输出来实现的。由此产生的多样性意味着,随机森林比单个决策树更容易拟合。这种合奏方法意味着即使在复杂的数据集中,随机森林也擅长处理嘈杂的数据。
多功能性
就像建造的决策树一样,随机森林的用途高度使用。他们可以处理回归和分类任务,使其适用于广泛的问题。随机森林还可以与大型,功能丰富的数据集合作,并且可以处理数值和分类数据。
特征重要性
随机森林具有内置的能力来估计特定特征的重要性。作为训练过程的一部分,随机森林输出的分数可以测量如果去除特定功能,则模型的准确性会发生多大变化。通过平均每个特征的分数,随机森林可以提供可量化的特征重要性度量。然后可以删除不太重要的特征,以创建更有效的树木和森林。
随机森林的缺点
尽管随机森林提供了许多好处,但与单个决策树相比,它们更难解释,而训练的成本更高,并且与其他模型相比,它们的输出预测可能更慢。
复杂
尽管随机的森林和决策树有很多共同点,但随机森林很难解释和可视化。这种复杂性之所以出现,是因为随机森林使用数百或数千个决策树。当模型是一种要求时,随机森林的“黑匣子”性质是一个严重的缺点。
计算成本
培训数百或数千个决策树需要比训练单个决策树更多的处理能力和记忆。当涉及大型数据集时,计算成本可能会更高。这项庞大的资源需求可能会导致更高的货币成本和更长的培训时间。结果,在诸如Edge Computing之类的情况下,随机森林可能不实用,因为计算能力和记忆都稀少。但是,随机森林可以并行化,这可以帮助降低计算成本。
较慢的预测时间
随机森林的预测过程涉及穿越森林中的每棵树并汇总其输出,这比使用单个模型固有的速度慢。与逻辑回归或神经网络(尤其是对于含有深树木的大森林)相比,此过程可能导致预测时间较慢。对于时间本质上的用例(例如高频交易或自动驾驶汽车),这种延迟可能会过时。