
語法作者身份為教師提供了對學生人工智慧寫作過程的新見解
已發表: 2024-10-15在人工智慧教育時代的第二個完整年頭,學術領袖發現自己處於人工智慧發展的獨特時間點。圍繞人工智慧的討論實際上已經從“我們應該嗎?”轉變為“我們應該嗎?”到“我們怎麼做才是正確的?”
在解決這個問題兩年多後,Grammarly 部署了一款新產品 Grammarly Authorship,旨在幫助教育領導者開發一種更周到的方法來進行人工智慧創新,同時保持學術誠信、學生學習和信任。稍後會詳細介紹。
但首先,如果您正在閱讀本文,您可能知道人工智慧不會消失,事實上,它在學術界越來越流行。根據數位教育委員會進行的一項調查,86% 的學生在學習中定期使用人工智慧,其中 54% 每週使用一次。教師的使用率仍然落後於學生,但在過去 18 個月裡,教師的人工智慧使用量也有所增長,根據 Tyton Partners 的最新調查“上課時間”,超過三分之一的人每月使用人工智慧工具。
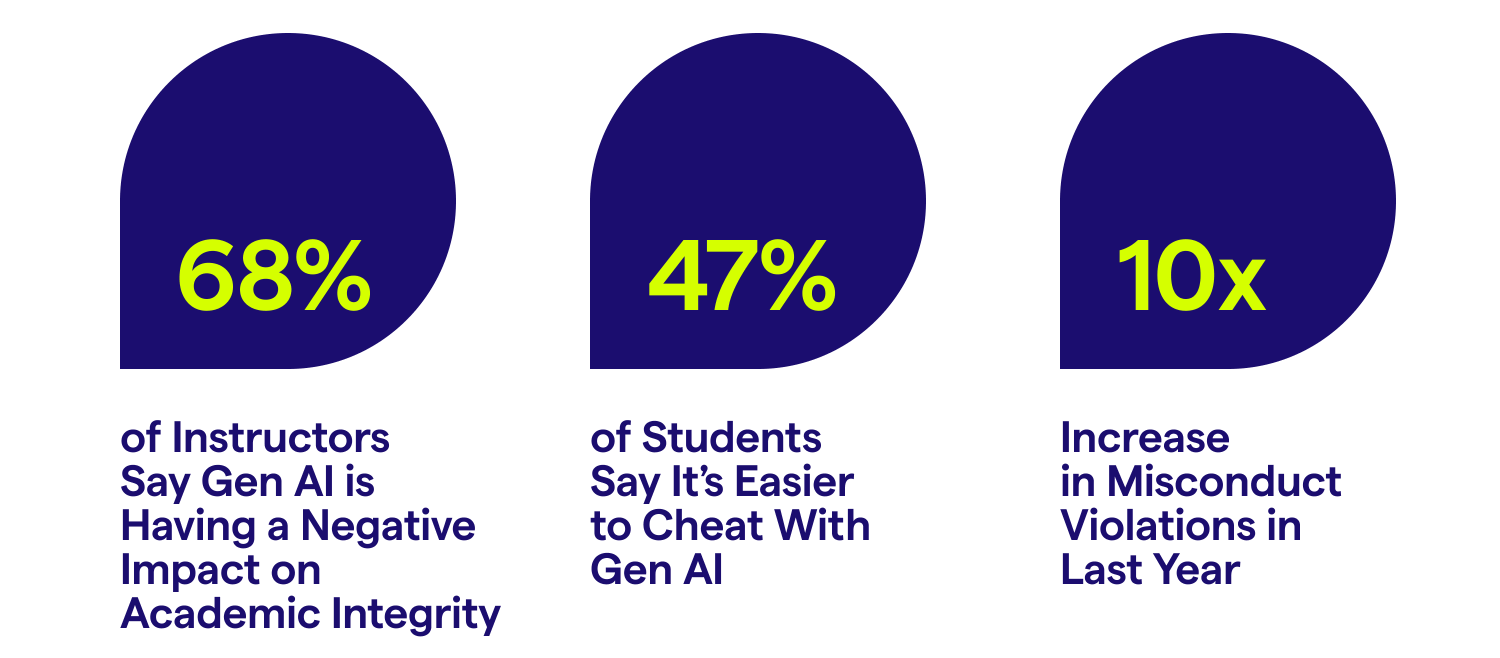
對大多數教育工作者來說,人工智慧的使用並不是問題所在,而是它對學術誠信的影響。近 70% 的教師直言不諱地表示人工智慧對學術誠信產生負面影響。這項假設得到了近一半學生(47%)的驗證,他們公開承認使用新一代人工智慧更容易作弊。這些擔憂導致校園內的誠信違規行為穩定增加,而雪梨大學這一典型機構的違規行為在過去一年增加了 10 倍。
高等教育的信任問題
迄今為止,高等教育一直試圖透過檢測來平衡人工智慧和學術誠信。不同供應商的檢測技術各不相同,但所有解決方案的共同點是依賴自主開發的演算法,該演算法估計文字是基於模式識別的人工智慧產生的可能性。因此,檢測在廣泛部署時會帶來幾個問題:
- 對於使用這些演算法的教師和被標記的學生來說,標記文本的演算法的本質是一個謎,導致缺乏透明度和為什麼特定文本被標記的洞察力。
- 由於這些演算法本質上是預測性的,並且基於事後文字分析,因此它們所做或不標記的內容可能不準確。研究表明,檢測器可能會對非英語母語作家和神經多樣化的學習者產生偏見,當用於懲罰學生時,可能會導致更大的公平差距。
- 最後,這些演算法始終會追隨大型語言模型(LLM)供應商驅動的創新。現實情況是,探測器正在與不斷發展的技術進行軍備競賽,這種技術將繼續以越來越快的速度模仿人類的思維和書寫;賓州大學最近發表的一項研究表明,即使是最新的檢測模型也經常無法準確識別最新模型中人工智慧產生的文字。
儘管存在這些現實,人工智慧探測器仍然在教學過程中發揮巨大作用。它們的使用對高效學習所必需的學生和教育者之間的關係產生了不利影響。
許多機構目前普遍存在信任赤字。學生不相信他們的教師會清楚、透明地表達他們的期望和回饋。教師缺乏信任,他們的學生在能夠使用人工智慧這樣強大的技術時,會以合乎道德的方式使用它並優化他們的學習。
對於那些盡最大努力完成作業的好心學生來說,這會造成一種恐懼狀態,他們只能等待,看看他們的作業是否會被標記為作弊。對於教師來說,他們現在需要花更多的時間用不精確的技術來監管人工智慧的使用,而不是提供他們受僱灌輸的主題專業知識。
為了在人工智慧時代有效教學,教師需要超越檢測的工具和策略,以便他們能夠忠於教育學生的目標,同時指導他們如何熟練和負責任地使用人工智慧。
透過 Grammarly Authorship 從偵測到透明
人工智慧檢測可能是解決人工智慧學術不端行為擔憂的必要權宜之計。然而,雖然這些工具可以提供見解,但它們常常忽略人工智慧如何使用以及為何使用的細微差別。簡單地標記人工智慧生成的文本並不能揭示學生的作品有多少是真正屬於他們自己的,也不能揭示人工智慧工具是如何被用來增強他們的思維的。
語法作者身份超越了這一點。它不是試圖在事後檢測人工智慧生成的內容,而是提供了一個了解整個寫作和編輯過程的視窗。透過追蹤文本的來源(無論是輸入、貼上或使用人工智慧工具編輯),作者身份為教師提供了關於如何在學生與人工智慧協作過程中創建作業的清晰、可驗證的資訊。
它是如何運作的
Grammarly Authorship 現在僅在Google Docs 中作為測試版提供,它利用Grammarly 的瀏覽器內以及最終在設備上的存在,在複製和鍵入的文本從用戶的瀏覽器窗口移動到剪貼板到文檔時對其進行歸屬。由於 Grammarly 在超過 500,000 個應用程式和網站中可用,因此它能夠獨特地識別使用者何時將文字帶入文件正文並了解文字的來源。測試階段應用的唯一演算法邏輯是將特定網站分類為產生人工智慧。

Authorship Beta 能夠將來自 Grammarly、ChatGPT、Gemini、Claude 或 CoPilot 的文字歸類為生成式 AI。作者身分也會對使用者在 Google 文件正文中執行的特定於 Grammarly 的文字操作進行分類,包括使用 Grammarly 的 LLM 修改的生成文字或使用 Grammarly 的傳統機器學習模型編輯的文字。這些差異在人工智慧時代非常重要,可以幫助教師更明確地了解給定的寫作作業中什麼是可以接受的,什麼是不可以接受的。例如,教授可能同意學生自己寫單字並使用 Grammarly 的 LLM 來解釋這些單字,但不同意學生使用 Grammarly 或 ChatGPT 產生文本,然後將其合併到文件中。作者身份清楚地闡明了這些區別,使學生能夠在提交之前透過即時數據了解他們是否遵守教育者的指導方針。

值得注意的是,未經學生同意,作者身分不會追蹤任何內容。在收集任何資料或見解之前,學生在開啟空白的 Google 文件時必須主動啟用追蹤。他們還必須授予對剪貼簿的存取權限;否則,Grammarly 以外基於瀏覽器的文字將被視為「從已知來源複製」。這是設計使然,因為我們希望學生感到有權啟用跟踪,以保護自己免受抄襲的虛假指控,並確保作者身份符合他們的最大利益,幫助他們做得最好。最終,學生是負責與教師分享作者身份報告的人,並且可以在準備提交寫作作業時這樣做。
值得注意的是,這與當今的人工智慧檢測有很大不同,而當今的人工智慧檢測主要由教師和機構在學生提交作業後部署。透過作者身份,先前單方面的數據變得雙面、透明且可操作,消除了人工智慧檢測中隱含的懷疑和不確定性。
教師應如何使用文法作者身份?
雖然作者權的設計初衷是學生至上,但我們知道,個別教師理應擁有很大的自主權,可以向學生推薦他們在作業中使用的內容。我們也相信,學生希望以實際學習的形式獲得教育投資的真正回報,讓他們做好批判性思考的準備,並在畢業後等待他們的複雜世界中做出有效的決定。最後,我們相信人工智慧時代的寫作,從學術寫作到專業寫作,都將是與人工智慧的合作,這取決於作者評估寫作背景並相應調整人工智慧使用的能力。在某些情況下,可能根本不應該使用人工智慧。在其他情況下,將實際的文字生成外包給人工智慧可能是完全有意義的。我們需要的是了解什麼是好的寫作,以及對何時適合或不依賴人工智慧做出良好判斷的能力。
為此,我們鼓勵教師建議學生打開作者身份,並提交作者身份報告以及完成的寫作作業,作為學習工具,幫助學生和教育工作者適應人工智慧時代的寫作。
為了充分利用 Grammarly Authorship,教師可以使用它來客觀、清晰地了解學生作業中使用的文本來源,而無需依賴人工智慧偵測器。該工具可以更深入地了解學生如何完成作業,幫助您快速識別課程等級的趨勢並找出關鍵教學領域。透過向教師和學生提供相同的訊息,文法作者身份促進了圍繞作業的寫作選擇進行更實質的討論。它還允許您透過作者重播來確定個別學生需要改進的領域,從而實現更個性化的指導,以提高學生的編輯和起草技能。此外,您可以快速識別學生何時可能使用了與作業不相符的資源,並及早解決這些問題,將潛在的學術誠信違規行為轉變為學習機會。
Grammarly不建議教師使用作者身分作為監管學生作業的方式,從而縮短植根於學生學習的實質對話。換句話說,作者身分不應被用作篩選學生作品過多或過少使用人工智慧的方式,也不應被用作懲罰學生不當使用人工智慧的單一數據點。
賦能教師運用人工智慧進行創新
對於希望擁抱人工智慧同時保持學術誠信的教師來說,語法作者身份是一個遊戲規則的改變者。透過提供寫作過程的透明度,作者身份使教育工作者能夠超越懲罰性措施,轉向在作業中採用協作、建設性的人工智慧方法。這種轉變不僅保證了教育質量,也為學生提供了在人工智慧驅動的世界中茁壯成長所需的技能。
隨著人工智慧不斷重塑教育的未來,Grammarly Authorship 為負責任的創新提供了路線圖。教師現在可以利用人工智慧作為學習工具,相信學生正在使用它來增強而不是取代自己的智力貢獻。這種方法對於建立信任、促進創新和確保學術誠信始終是高等教育的核心至關重要。