
生成對抗網路基礎:您需要了解的內容
已發表: 2024-10-08生成對抗網路 (GAN) 是一種強大的人工智慧 (AI) 工具,在機器學習 (ML) 領域有著廣泛的應用。本指南探討了 GAN、它們的運作方式、應用以及它們的優點和缺點。
目錄
- 什麼是 GAN?
- GAN 與 CNN
- GAN 的工作原理
- GAN 的類型
- GAN 的應用
- GAN 的優點
- GAN 的缺點
什麼是生成對抗網路?
生成對抗網路(GAN)是一種深度學習模型,通常用於無監督機器學習,但也適用於半監督和監督學習。 GAN 用於產生類似於訓練資料集的高品質資料。作為生成式人工智慧的一個子集,GAN 由兩個子模型組成:生成器和判別器。
1生成器:生成器建立合成資料。
2鑑別器:鑑別器評估生成器的輸出,區分訓練集中的真實資料和生成器所建立的合成資料。
這兩個模型競爭:生成器試圖欺騙鑑別器將產生的數據分類為真實數據,而鑑別器則不斷提高其檢測合成數據的能力。這種對抗過程一直持續到鑑別器無法再區分真實數據和生成數據為止。此時,GAN 能夠產生逼真的圖像、視訊和其他類型的資料。
GAN 與 CNN
GAN 和卷積神經網路 (CNN) 是深度學習中使用的強大神經網路類型,但它們在用例和架構方面存在顯著差異。
使用案例
- GAN:專門根據訓練資料產生真實的合成資料。這使得 GAN 非常適合圖像生成、圖像風格遷移和資料增強等任務。 GAN 是無監督的,這意味著它們可以應用於標記資料稀缺或不可用的場景。
- CNN:主要用於結構化資料分類任務,例如情感分析、主題分類和語言翻譯。由於其分類能力,CNN 也可以作為 GAN 中良好的判別器。然而,由於 CNN 需要結構化的、人工註釋的訓練數據,因此它們僅限於監督學習場景。
建築學
- GAN:由兩個模型組成-鑑別器和生成器-參與競爭過程。生成器創建圖像,而鑑別器對其進行評估,從而推動生成器隨著時間的推移生成越來越逼真的圖像。
- CNN:利用卷積層和池化操作從影像中提取和分析特徵。這種單模型架構專注於識別資料中的模式和結構。
總體而言,CNN 專注於分析現有的結構化數據,而 GAN 則致力於創建新的、真實的數據。
GAN 的工作原理
從較高層次來看,GAN 的工作原理是讓兩個神經網路(生成器和鑑別器)相互對抗。 GAN 的兩個元件都不需要特定類型的神經網路架構,只要所選架構能夠互相補充即可。例如,如果使用 CNN 作為影像生成的判別器,則生成器可能是反捲積神經網路 (deCNN),它會反向執行 CNN 過程。每個組件都有不同的目標:
- 生成器:產生高品質的數據,使鑑別器被愚弄,將其分類為真實數據。
- 鑑別器:準確地將給定的資料樣本分類為真實的(來自訓練資料集)或假的(由生成器產生)。
本次比賽是零和遊戲的一種實現,其中對一個模型的獎勵也是對另一個模型的懲罰。對於生成器來說,成功欺騙鑑別器會導致模型更新,從而增強其產生真實資料的能力。相反,當鑑別器正確識別假數據時,它會收到提高其檢測能力的更新。從數學上講,判別器的目標是最小化分類誤差,而生成器的目標是最大化分類誤差。
GAN 訓練過程
訓練 GAN 需要在多個時期交替使用生成器和判別器。 Epoch 是對整個資料集的完整訓練。這個過程一直持續到生成器產生的合成資料在大約 50% 的時間內欺騙了鑑別器。雖然這兩個模型都使用類似的演算法進行效能評估和改進,但它們的更新是獨立發生的。這些更新是使用稱為反向傳播的方法進行的,該方法測量每個模型的誤差並調整參數以提高效能。然後,最佳化演算法獨立調整每個模型的參數。
這是 GAN 架構的直覺表示,說明了生成器和判別器之間的競爭:
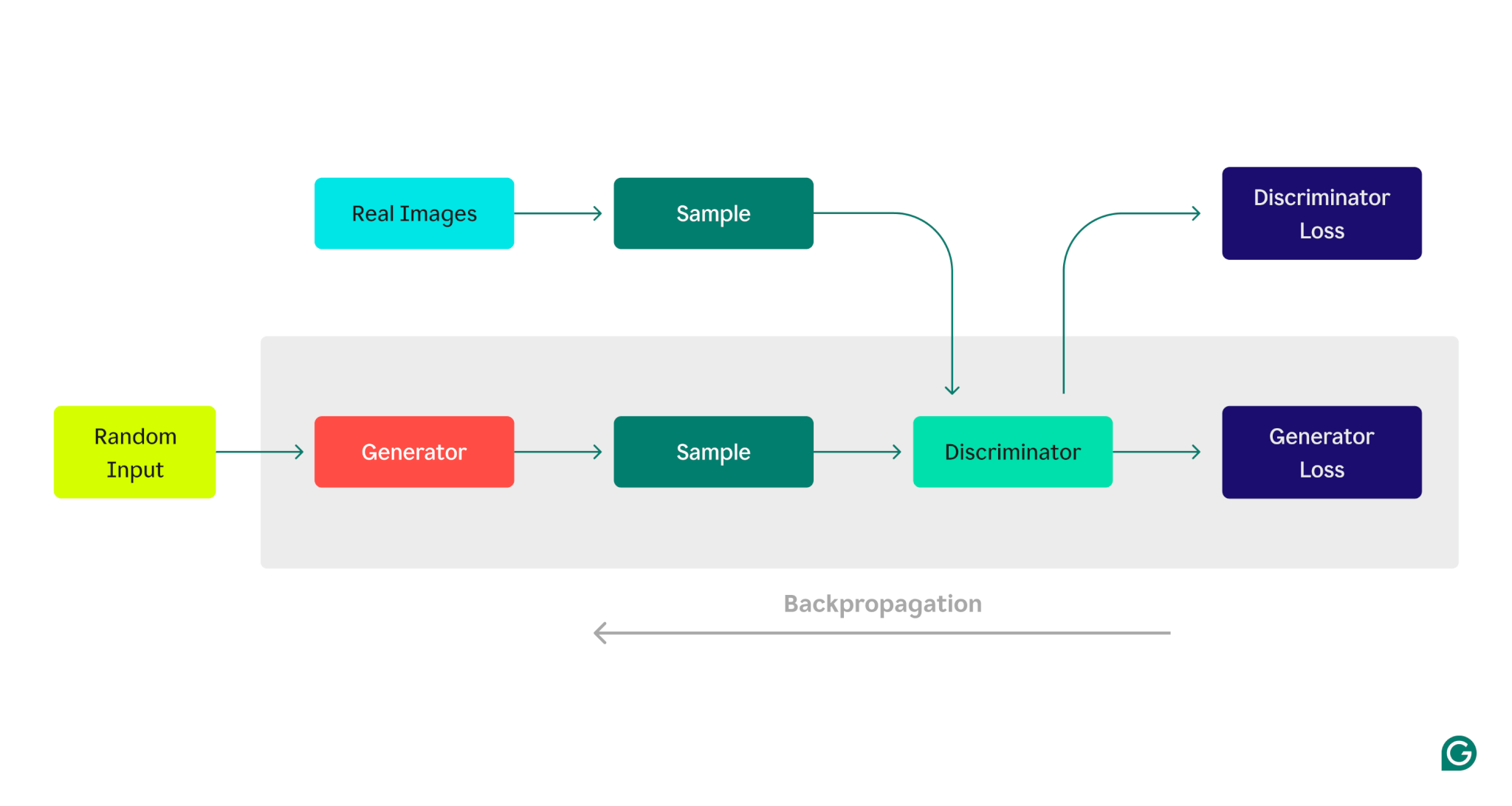
生成器訓練階段:
1生成器建立資料樣本,通常以隨機雜訊作為輸入開始。
2鑑別器將這些樣本分類為真實樣本(來自訓練資料集)或假樣本(由生成器產生)。
3根據鑑別器的回應,使用反向傳播更新生成器參數。

判別器訓練階段:
1使用生成器的目前狀態產生虛假資料。
2產生的樣本與訓練資料集中的樣本一起提供給鑑別器。
3使用反向傳播,鑑別器的參數根據其分類性能進行更新。
這種迭代訓練過程繼續進行,每個模型的參數根據其性能進行調整,直到生成器一致地產生鑑別器無法與真實資料可靠區分的資料。
GAN 的類型
在通常稱為普通 GAN 的基本 GAN 架構的基礎上,也針對各種任務開發和最佳化了其他專用類型的 GAN。下面描述了一些最常見的變體,但這不是詳盡的清單:
條件 GAN (cGAN)
條件 GAN 或 cGAN 使用稱為條件的附加資訊來指導模型在更通用的資料集上進行訓練時產生特定類型的資料。條件可以是類別標籤、基於文字的描述或資料的其他類型的分類資訊。例如,假設您只需要產生暹羅貓的圖像,但您的訓練資料集包含各種貓的圖像。在 cGAN 中,您可以使用貓的類型來標記訓練圖像,模型可以使用它來學習如何僅生成暹羅貓的圖片。
深度卷積 GAN (DCGAN)
深度卷積 GAN(或 DCGAN)針對影像生成進行了最佳化。在 DCGAN 中,生成器是深度嵌入卷積神經網路 (deCNN),鑑別器是深度 CNN。由於 CNN 能夠捕捉空間層次結構和模式,因此更適合處理和生成影像。 DCGAN 中的生成器使用上採樣和轉置卷積層來創建比多層感知器(一種透過權衡輸入特徵做出決策的簡單神經網路)生成的影像品質更高的影像。類似地,鑑別器使用卷積層從影像樣本中提取特徵,並準確地將其分類為真或假。
循環GAN
CycleGAN 是一種 GAN,旨在從一種類型的影像產生另一種類型的影像。例如,CycleGAN 可以將小鼠的圖像轉換為大鼠,或將狗的圖像轉換為土狼。 CycleGAN 能夠執行這種影像到影像的轉換,而無需對配對資料集(即包含基礎影像和所需轉換的資料集)進行訓練。此功能是透過使用兩個生成器和兩個鑑別器而不是普通 GAN 使用的一對來實現的。在 CycleGAN 中,一個生成器將影像從基礎影像轉換為變換後的版本,而另一個生成器則以相反的方向執行轉換。同樣,每個鑑別器檢查特定的圖像類型以確定它是真實的還是虛假的。然後,CycleGAN 使用一致性檢查來確保將影像轉換為其他樣式並傳回原始影像。
GAN 的應用
由於其獨特的架構,GAN 已應用於一系列創新用例,但其效能高度依賴特定任務和資料品質。一些更強大的應用程式包括文字到圖像生成、資料增強以及視訊生成和操作。
文字到圖像的生成
GAN 可以根據文字描述產生圖像。該應用程式在創意產業中很有價值,它允許作者和設計師可視化文本中描述的場景和人物。雖然 GAN 通常用於此類任務,但其他生成式 AI 模型(例如 OpenAI 的 DALL-E)使用基於 Transformer 的架構來實現類似的結果。
數據增強
GAN 對於數據增強很有用,因為它們可以產生類似於真實訓練數據的合成數據,儘管準確度和真實度可能會根據特定用例和模型訓練而有所不同。此功能在機器學習中對於擴展有限資料集和增強模型效能特別有價值。此外,GAN 也提供了維護資料隱私的解決方案。在醫療保健和金融等敏感領域,GAN 可以產生合成數據,保留原始數據集的統計屬性,而不會洩露敏感資訊。
視訊生成和操作
GAN 在某些視訊生成和操作任務中表現出了良好的前景。例如,GAN 可用於從初始視訊序列產生未來幀,有助於預測行人運動或預測自動駕駛車輛的道路危險等應用。然而,這些應用仍在積極研究和開發中。 GAN 也可用於產生完全合成的影片內容,並透過逼真的特效增強影片。
GAN 的優點
GAN 具有多種獨特的優勢,包括產生真實合成資料、從不配對資料中學習以及執行無監督訓練的能力。
高品質的合成數據生成
GAN 的架構允許他們產生可以在數據增強和視訊創建等應用中近似真實世界數據的合成數據,儘管這些數據的品質和精度在很大程度上取決於訓練條件和模型參數。例如,DCGAN 利用 CNN 進行最佳影像處理,擅長產生逼真的影像。
能夠從不配對的數據中學習
與某些 ML 模型不同,GAN 可以從資料集中學習,而無需成對的輸入和輸出範例。這種靈活性使得 GAN 能夠廣泛應用於配對資料稀缺或不可用的任務中。例如,在圖像到圖像的翻譯任務中,傳統模型通常需要圖像資料集及其轉換來進行訓練。相較之下,GAN 可以利用更廣泛的潛在資料集進行訓練。
無監督學習
GAN 是一種無監督的機器學習方法,這意味著它們可以在沒有明確指導的情況下對未標記的資料進行訓練。這是特別有利的,因為標記資料是一個耗時且昂貴的過程。 GAN 能夠從未標記的資料中學習,這使得它們對於標記資料有限或難以取得的應用很有價值。 GAN 也可以適用於半監督和監督學習,從而允許它們也使用標記資料。
GAN 的缺點
雖然 GAN 是機器學習中的強大工具,但其架構有一系列獨特的缺點。這些缺點包括對超參數的敏感度、高運算成本、收斂失敗、稱為模式崩潰的現象。
超參數敏感性
GAN 對超參數很敏感,這些參數是在訓練之前設定的,而不是從資料中學習的。範例包括網路架構和單次迭代中使用的訓練範例的數量。這些參數的微小變化可能會顯著影響訓練過程和模型輸出,因此需要針對實際應用進行廣泛的微調。
計算成本高
由於其複雜的架構、迭代訓練過程和超參數敏感性,GAN 通常會產生高昂的運算成本。成功訓練 GAN 需要專門且昂貴的硬體以及大量時間,這對於許多希望利用 GAN 的組織來說可能是一個障礙。
收斂失敗
工程師和研究人員可以花費大量時間來試驗訓練配置,然後才能達到模型輸出變得穩定且準確的可接受速率(稱為收斂速率)。 GAN 中的收斂可能非常難以實現,並且可能不會持續很長時間。收斂失敗是指鑑別器無法充分區分真實數據和虛假數據,導致準確度約為 50%,因為它沒有獲得識別真實數據的能力,這與成功訓練期間達到的預期平衡不同。一些 GAN 可能永遠無法達到收斂,並且可能需要專門的分析來修復。
模式崩潰
GAN 很容易出現一種稱為模式崩潰的問題,即生成器創建的輸出範圍有限,並且無法反映現實世界資料分佈的多樣性。這個問題源自於 GAN 架構,因為生成器過於專注於產生可以欺騙鑑別器的數據,導致鑑別器產生類似的範例。