
什麼是神經網路?
已發表: 2024-06-26什麼是神經網路?
神經網路是更廣泛的機器學習 (ML) 領域內的一種深度學習模型,可模擬人腦。 它透過分層排列的互連節點或神經元(輸入層、隱藏層和輸出層)處理資料。 每個節點執行簡單的計算,有助於模型識別模式和做出預測的能力。
深度學習神經網路在處理影像和語音辨識等複雜任務方面特別有效,是許多人工智慧應用的重要組成部分。 神經網路架構和訓練技術的最新進展大大增強了人工智慧系統的能力。
神經網路的結構如何
如其名稱所示,神經網路模型的靈感來自神經元,即大腦的建構模組。 成年人有大約 850 億個神經元,每個神經元與大約 1,000 個其他神經元相連。 一個腦細胞透過發送稱為神經傳導物質的化學物質與另一個腦細胞進行交流。 如果接收細胞獲得足夠的這些化學物質,它就會興奮並將自己的化學物質發送到另一個細胞。
有時稱為人工神經網路 (ANN) 的基本單位是節點,它不是一個單元,而是一個數學函數。 就像神經元一樣,如果它們獲得足夠的輸入,它們就會與其他節點進行通訊。
相似之處就到此為止。 神經網路的結構比大腦簡單得多,具有明確定義的層:輸入、隱藏和輸出。 這些層的集合稱為模型。 他們透過反覆嘗試人為地產生最接近期望結果的輸出來學習或訓練。 (稍後會詳細介紹。)
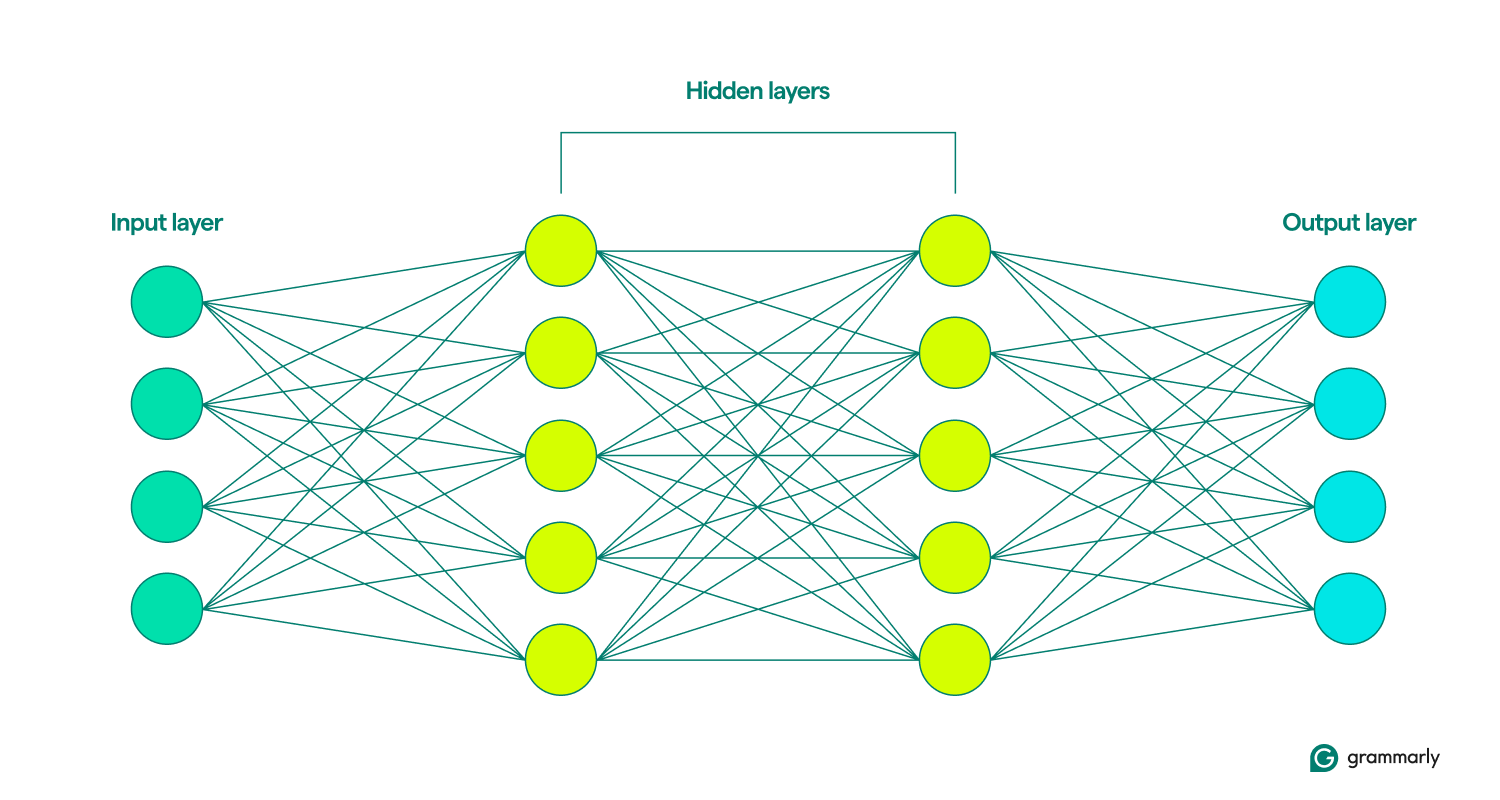
輸入層和輸出層非常不言自明。 神經網路所做的大部分工作都發生在隱藏層。 當節點被前一層的輸入啟動時,它會進行計算並決定是否將輸出傳遞到下一層的節點。 這些層之所以如此命名,是因為它們的操作對最終用戶來說是不可見的,儘管工程師可以透過一些技術來查看所謂的隱藏層中發生的情況。
當神經網路包含多個隱藏層時,它們被稱為深度學習網路。 現代深度神經網路通常有許多層,包括執行不同功能的專用子層。 例如,某些子層增強了網路考慮正在分析的直接輸入之外的上下文資訊的能力。
神經網路如何運作
想想嬰兒是如何學習的。 他們嘗試某件事,失敗,然後以不同的方式再試一次。 這個循環一遍又一遍地繼續,直到他們完善了行為。 這或多或少也是神經網路學習的方式。
在訓練的一開始,神經網路會進行隨機猜測。 輸入層上的節點隨機決定啟動第一個隱藏層中的哪些節點,然後這些節點隨機啟動下一層中的節點,依此類推,直到這個隨機過程到達輸出層。 (像 GPT-4 這樣的大型語言模型大約有 100 層,每層有數萬或數十萬個節點。)
考慮到所有的隨機性,模型會比較其輸出(這可能很糟糕)並找出它的錯誤程度。 然後,它調整每個節點與其他節點的連接,根據給定的輸入更改它們啟動的可能性。 它會重複執行此操作,直到其輸出盡可能接近所需的答案。
那麼,神經網路如何知道它們應該做什麼? 機器學習(ML)可以分為不同的方法,包括監督學習和無監督學習。 在監督式學習中,模型根據包含明確標籤或答案的資料進行訓練,例如與描述性文字配對的圖像。 然而,無監督學習涉及為模型提供未標記的數據,使其能夠獨立識別模式和關係。
這種訓練的常見補充是強化學習,模型根據回饋進行改進。 通常,這是由人類評估者提供的(如果您曾經對電腦的建議表示贊成或反對,那麼您就為強化學習做出了貢獻)。 儘管如此,模型也有辦法獨立迭代學習。
將神經網路的輸出視為預測是準確且有啟發性的。 無論是評估信用度還是產生歌曲,人工智慧模型的工作原理都是猜測最有可能正確的內容。 ChatGPT 等生成式人工智慧將預測更進一步。 它按順序工作,猜測剛剛輸出後應該發生什麼。 (稍後我們將討論為什麼這會出現問題。)
神經網路如何產生答案
一旦網路經過訓練,它如何處理它看到的資訊以預測正確的回應? 當你在ChatGPT介面中輸入「給我講一個關於仙女的故事」這樣的提示時,ChatGPT如何決定如何回應?
第一步是神經網路的輸入層將您的提示分解為小塊訊息,稱為標記。 對於圖像識別網絡,標記可能是像素。 對於使用自然語言處理 (NLP) 的網路(例如 ChatGPT),標記通常是一個單字、單字的一部分或非常短的短語。
一旦網路在輸入中註冊了標記,該資訊就會透過早期訓練的隱藏層傳遞。 它從一層傳遞到下一層的節點分析輸入的越來越大的部分。 這樣,NLP 網路最終可以解釋整個句子或段落,而不僅僅是一個單字或一個字母。
現在,網路可以開始製定其回應,它根據所訓練的所有內容對接下來會發生的事情進行一系列逐字預測。
考慮一下提示:“給我講一個關於仙女的故事。” 為了產生反應,神經網路分析提示以預測最可能的第一個單字。 例如,它可能確定「The」有 80% 的機會是最佳選擇,「A」有 10% 的機會,「Once」有 10% 的機會。 然後它隨機選擇一個數字:如果數字在 1 到 8 之間,則選擇「The」;如果數字在 1 到 8 之間,則選擇「The」; 如果是9,則選擇“A”; 如果是 10,則選擇「一次」。 假設隨機數為 4,對應於「The」。 然後,網路將提示更新為「告訴我一個關於仙女的故事。 The」並重複該過程來預測「The」之後的下一個單字。 這個循環繼續進行,每個新詞預測都基於更新的提示,直到產生一個完整的故事。
不同的網路會做出不同的預測。 例如,圖像識別模型可能會嘗試預測為狗的圖像賦予哪個標籤,並確定正確標籤有70% 的機率是“巧克力實驗室”,20% 的機率是“英國西班牙獵狗”,10% 的機率是“英國西班牙獵犬」。為「黃金獵犬」。 在分類的情況下,通常,網路會選擇最可能的選擇,而不是機率猜測。
神經網路的類型
以下概述了不同類型的神經網路及其運作方式。
- 前饋神經網路 (FNN):在這些模型中,資訊沿著一個方向流動:從輸入層,經由隱藏層,最後到達輸出層。此模型類型最適合更簡單的預測任務,例如偵測信用卡詐欺。
- 遞歸神經網路 (RNN):與 FNN 相比,RNN 在產生預測時會考慮先前的輸入。這使得它們非常適合語言處理任務,因為響應提示而產生的句子的結尾取決於句子的開始方式。
- 長短期記憶網絡 (LSTM): LSTM 選擇性地忘記訊息,這使它們能夠更有效地工作。這對於處理大量文字至關重要; 例如,Google翻譯 2016 年對神經機器翻譯的升級就依賴 LSTM。
- 卷積神經網路 (CNN): CNN 在處理影像時效果最佳。他們使用卷積層掃描整個影像並尋找線條或形狀等特徵。 這使得 CNN 能夠考慮空間位置,例如確定物件是否位於圖像的上半部分或下半部分,並且還可以識別形狀或物件類型,無論其位置如何。
- 生成對抗網路 (GAN): GAN 通常用於根據描述或現有影像生成新影像。它們的結構是兩個神經網絡之間的競爭:一個生成器網絡,試圖欺騙鑑別器網絡,使其相信虛假輸入是真實的。
- 變形金剛和注意力網絡:變形金剛是當前人工智慧能力爆炸性增長的原因。這些模型包含注意力聚光燈,使他們能夠過濾輸入以專注於最重要的元素,以及這些元素如何相互關聯,甚至跨越文字頁面。 Transformer 還可以訓練大量數據,因此 ChatGPT 和 Gemini 等模型被稱為大型語言模型 (LLM) 。
神經網路的應用
種類太多,無法一一列出,因此這裡精選了當今神經網路的使用方式,重點是自然語言。

寫作幫助:變形金剛改變了電腦幫助人們更好寫作的方式。Grammarly 等人工智慧寫作工具可以提供句子和段落層級的重寫,以提高語氣和清晰度。 這種模型類型也提高了基本語法建議的速度和準確性。 詳細了解 Grammarly 如何使用人工智慧。
內容生成:如果您使用過 ChatGPT 或 DALL-E,那麼您已經親身體驗了生成式 AI。 變形金剛徹底改變了電腦創造與人類產生共鳴的媒體的能力,從睡前故事到超現實的建築渲染。
語音辨識:電腦在辨識人類語音方面每天都在進步。新技術使模型能夠考慮更多的上下文,模型在識別說話者的意圖方面變得越來越準確,即使聲音本身可能有多種解釋。
醫學診斷和研究:神經網路擅長模式檢測和分類,越來越多地用於幫助研究人員和醫療保健提供者了解和解決疾病。例如,COVID-19 疫苗的快速開發在一定程度上要歸功於人工智慧。
神經網路的挑戰與局限性
以下簡要介紹了神經網路提出的一些問題,但不是全部。
偏差:神經網路只能從被告知的內容中學習。如果它暴露於性別歧視或種族主義內容,它的產出也可能是性別歧視或種族主義的。 這種情況可能發生在從非性別語言翻譯成性別語言的過程中,在沒有明確性別認同的情況下,刻板印象仍然存在。
過度擬合:訓練不當的模型可能會讀取過多的數據,並難以應對新的輸入。例如,主要針對特定種族的人進行訓練的臉部辨識軟體可能對其他種族的臉孔表現不佳。 或者,垃圾郵件過濾器可能會錯過新類型的垃圾郵件,因為它太專注於以前見過的模式。
幻覺:當今的生成式人工智慧在某種程度上使用機率來選擇生產什麼,而不是總是選擇排名最高的選擇。這種方法有助於它更具創造性並產生聽起來更自然的文本,但它也可能導致它做出完全錯誤的陳述。 (這也是法學碩士有時會犯下基本數學錯誤的原因。)不幸的是,除非您了解更多或與其他來源進行事實核查,否則這些幻覺很難被發現。
可解釋性:通常不可能確切地知道神經網路如何進行預測。雖然從試圖改進模型的人的角度來看,這可能令人沮喪,但它也可能產生後果,因為人工智慧越來越依賴做出極大影響人們生活的決策。 今天使用的一些模型並不是基於神經網絡,正是因為它們的創建者希望能夠檢查和理解過程的每個階段。
智慧財產權:許多人認為法學碩士在未經許可的情況下合併寫作和其他藝術作品,侵犯了版權。雖然他們往往不會直接複製受版權保護的作品,但眾所周知,這些模型會創建可能來自特定藝術家的圖像或措辭,甚至在提示時以藝術家獨特的風格創作作品。
功耗:變壓器模型的所有訓練和運行都消耗巨大的能量。事實上,幾年之內,人工智慧消耗的電力可能與瑞典或阿根廷一樣多。 這凸顯了在人工智慧開發中考慮能源和效率變得越來越重要。
神經網路的未來
預測人工智慧的未來是出了名的困難。 1970 年,一位頂尖的人工智慧研究人員預測,“三到八年內,我們將擁有一台具有普通人類一般智慧的機器。” (我們距離通用人工智慧(AGI)還不是很近。至少大多數人不這麼認為。)
然而,我們可以指出一些值得關注的趨勢。 更有效率的模型將降低功耗,並直接在智慧型手機等裝置上運行更強大的神經網路。 新的訓練技術可以用更少的訓練資料進行更有用的預測。 可解釋性方面的突破可以增加信任並為改善神經網路輸出鋪平新途徑。 最後,量子運算和神經網路的結合可能會帶來我們只能想像的創新。
結論
受人腦結構和功能啟發的神經網路是現代人工智慧的基礎。 它們擅長模式識別和預測任務,支撐著當今許多人工智慧應用,從圖像和語音識別到自然語言處理。 隨著架構和訓練技術的進步,神經網路持續推動人工智慧能力的顯著改進。
儘管神經網路具有潛力,但仍面臨偏差、過度擬合和高能耗等挑戰。 隨著人工智慧的不斷發展,解決這些問題至關重要。 展望未來,模型效率、可解釋性以及與量子運算整合的創新有望進一步擴大神經網路的可能性,從而有可能帶來更具變革性的應用。