
什麼是自動編碼器?初學者指南
已發表: 2024-10-28自動編碼器是深度學習的重要組成部分,特別是在無監督機器學習任務中。在本文中,我們將探討自動編碼器的工作原理、其架構以及可用的各種類型。您還將發現它們的實際應用程序,以及使用它們所涉及的優點和權衡。
目錄
- 什麼是自動編碼器?
- 自動編碼器架構
- 自動編碼器的類型
- 應用
- 優點
- 缺點
什麼是自動編碼器?
自動編碼器是深度學習中使用的神經網絡,用於學習輸入資料的高效、低維表示,然後用於重建原始資料。透過這樣做,該網路在訓練過程中學習資料最基本的特徵,而不需要明確的標籤,使其成為自我監督學習的一部分。自動編碼器廣泛應用於影像去雜訊、異常檢測和資料壓縮等任務,其中它們壓縮和重建資料的能力非常有價值。
自動編碼器架構
自動編碼器由三個部分組成:編碼器、瓶頸(也稱為潛在空間或代碼)和解碼器。這些組件協同工作以捕獲輸入資料的關鍵特徵並使用它們來產生準確的重建。
自動編碼器透過調整編碼器和解碼器的權重來最佳化其輸出,旨在產生保留關鍵特徵的輸入的壓縮表示。這種最佳化最大限度地減少了重建誤差,該誤差代表輸入和輸出資料之間的差異。
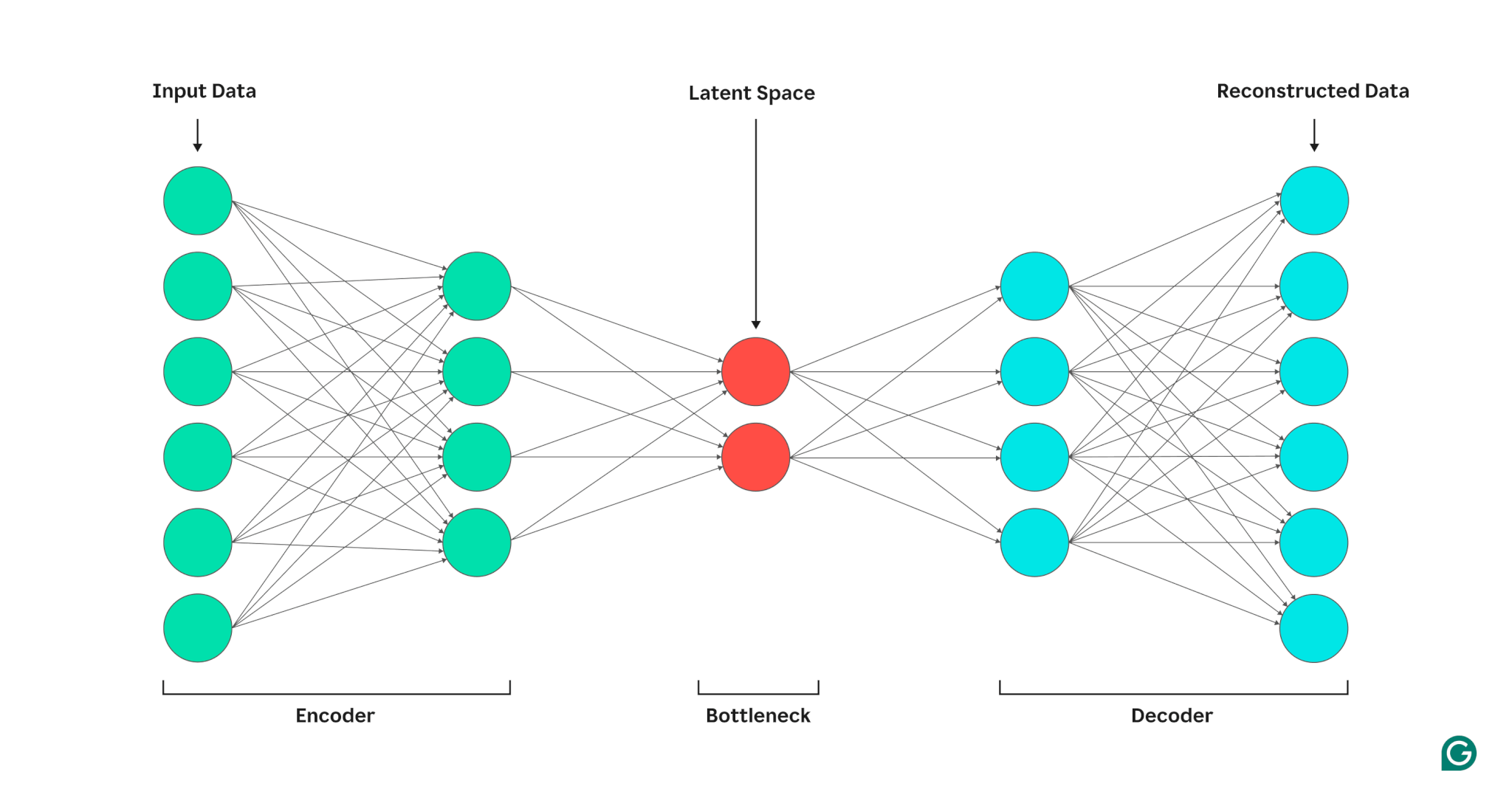
編碼器
首先,編碼器將輸入資料壓縮為更有效的表示。編碼器通常由多層組成,每層中的節點較少。隨著資料透過每一層進行處理,節點數量的減少迫使網路學習資料最重要的特徵,以建立可以儲存在每一層中的表示。這個過程稱為降維,將輸入轉換為資料關鍵特徵的緊湊摘要。編碼器中的關鍵超參數包括層數和每層神經元的數量,它們決定壓縮的深度和粒度,以及激活函數,它決定如何在每層表示和轉換資料特徵。
瓶頸
瓶頸也稱為潛在空間或程式碼,是在處理過程中儲存輸入資料的壓縮表示的位置。瓶頸節點數量少;這限制了可以儲存的資料量並決定了壓縮等級。瓶頸中的節點數量是一個可調的超參數,允許使用者控制壓縮和資料保留之間的權衡。如果瓶頸太小,自動編碼器可能會因遺失重要細節而錯誤地重建資料。另一方面,如果瓶頸太大,自動編碼器可能只是複製輸入數據,而不是學習有意義的通用表示。
解碼器
在最後一步中,解碼器使用在編碼過程中學到的關鍵特徵從壓縮形式重新建立原始資料。這種解壓的品質是使用重建誤差來量化的,重建誤差本質上是衡量重建數據與輸入數據的差異程度的指標。重建誤差通常使用均方誤差(MSE)來計算。由於 MSE 測量原始資料和重建資料之間的平方差,因此它提供了一種數學上簡單的方法來更嚴厲地懲罰較大的重建誤差。
自動編碼器的類型
有幾種類型的專用自動編碼器,每種都針對特定應用進行了最佳化,類似於其他神經網路。
去噪自動編碼器
去噪自動編碼器旨在從雜訊或損壞的輸入中重建乾淨的資料。在訓練過程中,有意將雜訊添加到輸入資料中,使模型能夠學習在存在雜訊的情況下保持一致的特徵。然後將輸出與原始的乾淨輸入進行比較。這個過程使得去噪自動編碼器在影像和音訊降噪任務中非常有效,包括消除視訊會議中的背景雜訊。

稀疏自動編碼器
稀疏自動編碼器在任何給定時間限制活動神經元的數量,從而鼓勵網路學習比標準自動編碼器更有效的資料表示。這種稀疏性約束是透過懲罰來強制執行的,該懲罰阻止激活比指定閾值更多的神經元。稀疏自動編碼器簡化了高維度數據,同時保留了基本特徵,這使得它們對於提取可解釋特徵和複雜資料集視覺化等任務很有價值。
變分自動編碼器 (VAE)
與典型的自動編碼器不同,VAE 透過將訓練資料中的特徵編碼為機率分佈而不是固定點來產生新資料。透過從該分佈中取樣,VAE 可以產生各種新數據,而不是根據輸入重建原始數據。此功能使 VAE 對於生成任務非常有用,包括合成資料生成。例如,在影像生成中,在手寫數字資料集上訓練的 VAE 可以根據訓練集創建新的、逼真的數字,但這些數字並非精確的複製品。
收縮自動編碼器
收縮自動編碼器在計算重建誤差期間引入了額外的懲罰項,鼓勵模型學習對雜訊具有穩健性的特徵表示。這種懲罰透過促進對輸入資料的微小變化不變的特徵學習來幫助防止過度擬合。因此,收縮自動編碼器比標準自動編碼器對噪音具有更強的穩健性。
卷積自動編碼器 (CAE)
CAE 利用卷積層捕捉高維度資料中的空間層次結構和模式。卷積層的使用使得 CAE 特別適合處理影像資料。 CAE 通常用於影像壓縮和影像異常檢測等任務。
自動編碼器在人工智慧的應用
自動編碼器有多種應用,例如降維、影像去噪和異常檢測。
降維
自動編碼器是在保留關鍵特徵的同時降低輸入資料維度的有效工具。此過程對於可視化高維資料集和壓縮資料等任務非常有價值。透過簡化數據,降維還可以提高運算效率,降低規模和複雜性。
異常檢測
透過學習目標資料集的關鍵特徵,自動編碼器可以在提供新輸入時區分正常資料和異常資料。高於正常的重建錯誤率表示偏離正常。因此,自動編碼器可以應用於預測維護和電腦網路安全等不同領域。
去噪
去噪自動編碼器可以透過學習從雜訊訓練輸入重建雜訊資料來清理雜訊資料。這種功能使得去噪自動編碼器對於影像優化等任務非常有價值,包括提高模糊照片的品質。去噪自動編碼器在訊號處理中也很有用,它們可以清除雜訊訊號,以實現更有效的處理和分析。
自動編碼器的優點
自動編碼器具有許多關鍵優勢。其中包括從未標記資料中學習的能力、無需顯式指令即可自動學習特徵以及提取非線性特徵的能力。
能夠從未標記的數據中學習
自動編碼器是一種無監督的機器學習模型,這意味著它們可以從未標記的資料中學習底層資料特徵。此功能意味著自動編碼器可以應用於標記資料可能稀缺或不可用的任務。
自動特徵學習
標準特徵提取技術,例如主成分分析 (PCA),在處理複雜和/或大型資料集時通常不切實際。由於自動編碼器在設計時考慮了降維等任務,因此它們可以自動學習資料中的關鍵特徵和模式,而無需手動特徵設計。
非線性特徵提取
自動編碼器可以處理輸入資料中的非線性關係,使模型能夠從更複雜的資料表示中捕捉關鍵特徵。這種能力意味著自動編碼器比只能處理線性資料的模型具有優勢,因為它們可以處理更複雜的資料集。
自動編碼器的局限性
與其他機器學習模型一樣,自動編碼器也有自己的一系列缺點。其中包括缺乏可解釋性、需要大量訓練資料集才能表現良好以及泛化能力有限。
缺乏可解釋性
與其他複雜的機器學習模型類似,自動編碼器缺乏可解釋性,這意味著很難理解輸入資料和模型輸出之間的關係。在自動編碼器中,出現這種可解釋性的缺乏是因為自動編碼器會自動學習特徵,而不是傳統模型,其中特徵是明確定義的。這種機器生成的特徵表示通常是高度抽象的,並且往往缺乏人類可解釋的特徵,使得很難理解表示中每個組成部分的含義。
需要大量訓練資料集
自動編碼器通常需要大型訓練資料集來學習關鍵資料特徵的通用表示。給定較小的訓練資料集,自動編碼器可能會過度擬合,導致在呈現新資料時泛化能力較差。另一方面,大型資料集為自動編碼器提供了必要的多樣性,以學習可應用於各種場景的資料特徵。
對新數據的概括有限
在一個資料集上訓練的自動編碼器通常具有有限的泛化能力,這意味著它們無法適應新的資料集。出現這種限制是因為自動編碼器適合基於給定資料集中的突出特徵的資料重建。因此,自動編碼器通常在訓練期間從資料中丟棄較小的細節,並且無法處理不符合廣義特徵表示的資料。