
什麼是機器學習中的決策樹?
已發表: 2024-08-14決策樹是資料分析師機器學習工具包中最常用的工具之一。在本指南中,您將了解什麼是決策樹、它們是如何建立的、各種應用程式、優點等等。
目錄
- 什麼是決策樹?
- 決策樹術語
- 決策樹的類型
- 決策樹如何運作
- 應用領域
- 優點
- 缺點
什麼是決策樹?
在機器學習 (ML) 中,決策樹是一種類似流程圖或決策圖的監督學習演算法。與許多其他監督學習演算法不同,決策樹可用於分類和迴歸任務。資料科學家和分析師在探索新資料集時經常使用決策樹,因為它們易於建立和解釋。此外,決策樹可以幫助識別重要的資料特徵,這些特徵在應用更複雜的機器學習演算法時可能有用。
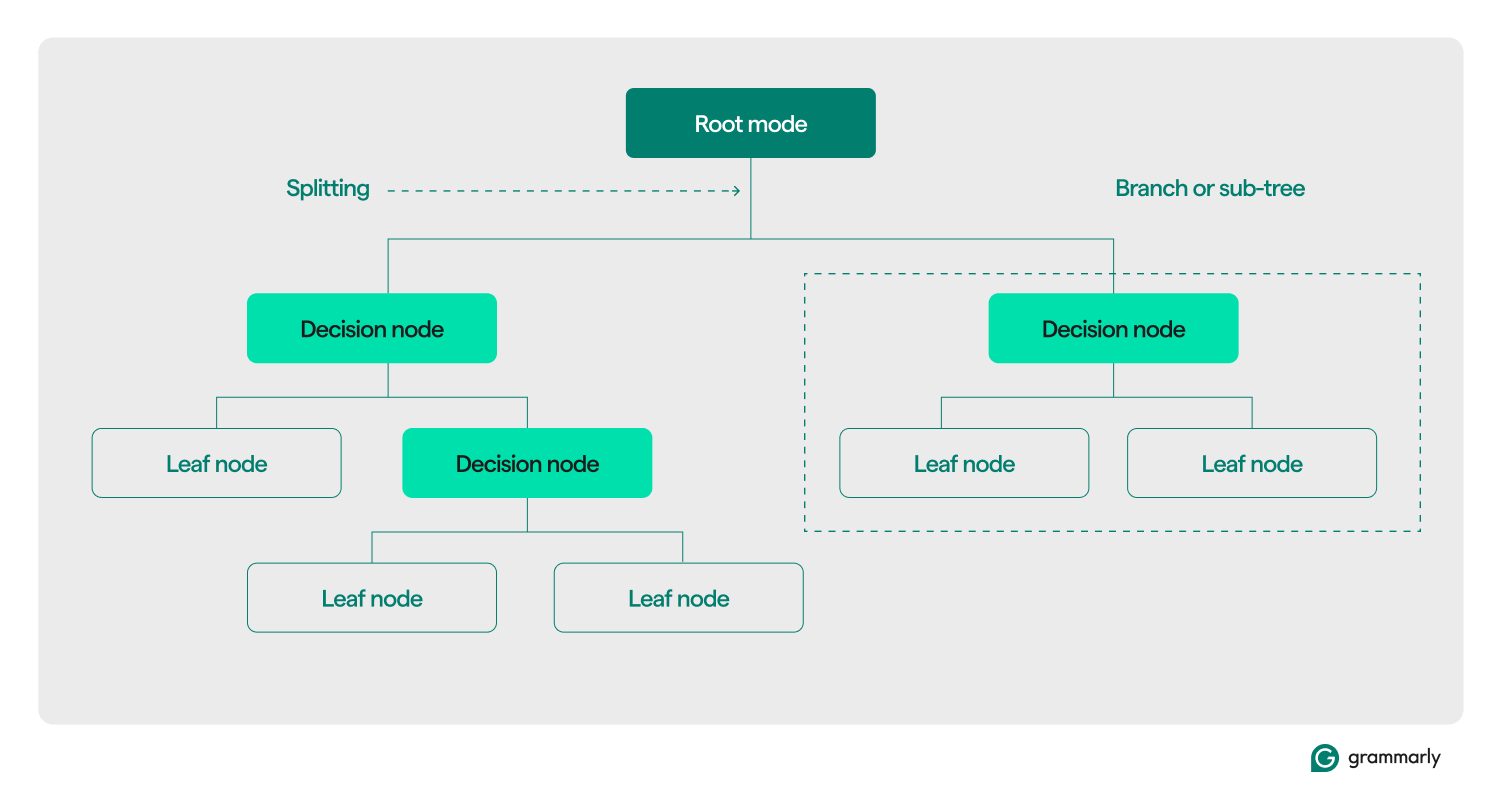
決策樹術語
在結構上,決策樹通常由三個組件組成:根節點、葉節點和決策(或內部)節點。就像其他領域中的流程圖或樹一樣,樹中的決策通常沿著一個方向(向下或向上)移動,從根節點開始,經過一些決策節點,最後到特定的葉節點。每個葉節點將訓練資料的子集連接到標籤。該樹是透過機器學習訓練和優化過程組裝而成的,建造完成後,它可以應用於各種資料集。
以下是對其餘術語的更深入探討:
- 根節點:包含決策樹將詢問的一系列有關資料的問題中的第一個問題的節點。此節點將連接到至少一個(但通常是兩個或多個)決策節點或葉節點。
- 決策節點(或內部節點):包含問題的附加節點。決策節點將恰好包含一個有關資料的問題,並根據回應將資料流定向到其子節點之一。
- 子節點:根節點或決策節點指向的一個或多個節點。它們代表決策過程在分析資料時可以採取的後續選項清單。
- 葉節點(或稱終端節點):指示決策過程已完成的節點。一旦決策過程到達葉節點,它將傳回葉節點的值作為其輸出。
- 標籤(class、category):通常是由葉節點與一些訓練資料關聯的字串。例如,葉子可能會將「滿意的客戶」標籤與決策樹 ML 訓練演算法所呈現的一組特定客戶相關聯。
- 分支(或子樹):這是由樹中任意點的決策節點及其所有子節點及其子節點(一直到葉節點)所組成的節點集。
- 修剪:通常對樹執行的最佳化操作,以使其更小並幫助其更快地返回輸出。剪枝通常指的是“後剪枝”,它涉及在機器學習訓練過程構建樹後通過演算法刪除節點或分支。 「預剪枝」是指決策樹在訓練過程中可以生長的深度或大小設定任意限制。這兩個過程都強制執行決策樹的最大複雜性,通常透過其最大深度或高度來衡量。較不常見的最佳化包括限制決策節點或葉節點的最大數量。
- 分裂:訓練期間在決策樹上執行的核心轉換步驟。它涉及將根或決策節點劃分為兩個或多個子節點。
- 分類:一種機器學習演算法,試圖找出最有可能應用於一段資料的計算方法(從恆定且離散的類別、類別或標籤清單中)。它可能會嘗試回答諸如“一周中的哪一天最適合預訂航班?”之類的問題。以下詳細介紹分類。
- 迴歸:一種嘗試預測連續值的 ML 演算法,該值可能並不總是有界限。它可能會嘗試回答(或預測答案)諸如“有多少人可能預訂下週二的航班?”之類的問題。我們將在下一節中詳細討論回歸樹。
決策樹的類型
決策樹通常分為兩類:分類樹和迴歸樹。可以建立特定的樹以應用於分類、回歸或這兩種用例。大多數現代決策樹使用 CART(分類和回歸樹)演算法,該演算法可以執行這兩種類型的任務。
分類樹
分類樹是最常見的決策樹類型,嘗試解決分類問題。從問題的可能答案清單中(通常像“是”或“否”一樣簡單),分類樹會在詢問有關其所提供的數據的一些問題後選擇最有可能的答案。它們通常以二元樹的形式實現,這意味著每個決策節點恰好有兩個子節點。
分類樹可能會嘗試回答多項選擇問題,例如“該客戶滿意嗎?”或“該客戶可能會造訪哪家實體店?”或“明天適合去高爾夫球場嗎?”
衡量分類樹品質的兩種最常見的方法是基於資訊增益和熵:
- 資訊增益:當樹在得到答案之前提出的問題較少時,它的效率就會提高。資訊增益透過評估在每個決策節點中了解一段資料的更多資訊來衡量樹能夠「快速」獲得答案的速度。它評估是否在樹中首先提出最重要和最有用的問題。
- 熵:準確性對於決策樹標籤至關重要。熵指標透過評估樹產生的標籤來衡量這種準確性。他們評估隨機資料片段最終出現錯誤標籤的頻率以及接收相同標籤的所有訓練資料片段之間的相似性。
更高級的樹木質量測量包括基尼指數、增益比、卡方評估以及方差減少的各種測量。

迴歸樹
迴歸樹通常用於迴歸分析以進行進階統計分析或預測連續的、可能無界範圍的資料。給定一系列連續選項(例如,實數範圍內的零到無限大),回歸樹嘗試在提出一系列問題後預測給定資料片段的最可能匹配。每個問題都會縮小潛在答案的範圍。例如,迴歸樹可用於預測信用評分、業務線的收入或行銷影片的互動次數。
迴歸樹的準確度通常使用均方誤差或平均絕對誤差等指標來評估,這些指標計算一組特定預測與實際值的偏差程度。
決策樹如何運作
作為監督學習的一個例子,決策樹依賴格式良好的資料進行訓練。來源資料通常包含模型應學習預測或分類的值清單。每個值都應該有一個附加標籤和一個關聯特徵清單-模型應該學習與標籤關聯的屬性。
建造或訓練
在訓練過程中,決策樹中的決策節點根據一種或多種訓練演算法遞歸地分裂為更具體的節點。過程的人性化描述可能如下所示:
- 從連接到整個訓練集的根節點開始。
- 分割根節點:使用統計方法,根據資料特徵之一將決策分配給根節點,並將訓練資料分配給至少兩個單獨的葉節點,作為子節點連接到根。
- 遞歸地將第二步應用於每個子節點,將它們從葉節點轉變為決策節點。當達到某個限制時(例如,樹的高度/深度、每個節點的每個葉子中子元素的品質度量等)或資料用完(即每個葉子都包含資料),請停止與一個標籤完全相關的點)。
對於分類、回歸以及組合分類和回歸用例,每個節點考慮哪些特徵的決定有所不同。每個場景都有多種演算法可供選擇。典型的演算法包括:
- ID3(分類):優化熵與資訊增益
- C4.5(分類):ID3的更複雜版本,為資訊增益添加歸一化
- CART(分類/迴歸): 「分類與迴歸樹」;貪婪演算法,優化結果集中的雜質最少
- CHAID(分類/迴歸): “卡方自動互動偵測”;使用卡方測量而不是熵和資訊增益
- MARS(分類/回歸):使用分段線性近似來捕捉非線性
常見的訓練機制是隨機森林。隨機森林或隨機決策森林是建構許多相關決策樹的系統。可以使用訓練演算法的組合來並行訓練樹的多個版本。根據對樹木質量的各種測量,這些樹木的子集將用於產生答案。對於分類用例,傳回由最大數量的樹選擇的類別作為答案。對於回歸用例,答案是聚合的,通常作為單一樹的平均值或平均預測。
評估並使用決策樹
一旦建立了決策樹,它就可以對新資料進行分類或預測特定用例的值。保留樹性能指標並使用它們來評估準確性和錯誤頻率非常重要。如果模型與預期效能偏差太大,可能是時候根據新資料重新訓練或尋找其他機器學習系統來應用於該用例。
決策樹在機器學習的應用
決策樹在各領域都有廣泛的應用。以下是一些例子來說明它們的多功能性:
知情的個人決策
一個人可能會記錄有關他們去過的餐廳等數據。他們可能會追蹤任何相關細節,例如旅行時間、等待時間、提供的菜餚、營業時間、平均評論分數、費用和最近的訪問,以及個人訪問餐廳的滿意度分數。可以根據這些資料訓練決策樹來預測新餐廳可能的滿意度分數。
計算客戶行為的機率
客戶支援系統可能使用決策樹來預測或分類客戶滿意度。可以訓練決策樹來根據各種因素預測客戶滿意度,例如客戶是否聯繫了支援人員或重複購買,或根據應用程式內執行的操作。此外,它還可以納入滿意度調查或其他客戶回饋的結果。
幫助為業務決策提供信息
對於某些具有大量歷史資料的商業決策,決策樹可以為後續步驟提供估計或預測。例如,收集有關其客戶的人口統計和地理資訊的企業可以訓練決策樹來評估哪些新地理位置可能有利可圖或應該避免。決策樹還可以幫助確定現有人口統計資料的最佳分類邊界,例如確定在對客戶進行分組時要單獨考慮的年齡範圍。
高級 ML 和其他用例的功能選擇
決策樹結構是人類可讀和可理解的。一旦建立了樹,就可以確定哪些特徵與資料集最相關以及按什麼順序。這些資訊可以指導更複雜的機器學習系統或決策演算法的開發。例如,如果企業從決策樹中了解到客戶將產品的成本放在首位,那麼它可以將更複雜的機器學習系統集中在這種洞察力上,或者在探索更細微的功能時忽略成本。
機器學習中決策樹的優點
決策樹提供了幾個顯著的優勢,使其成為機器學習應用程式中的流行選擇。以下是一些主要優點:
建置快速且簡單
決策樹是最成熟、最容易理解的機器學習演算法之一。它們不依賴特別複雜的計算,並且可以快速、輕鬆地建置。只要所需資訊容易取得,在考慮問題的 ML 解決方案時,決策樹就是一個簡單的第一步。
易於人類理解
決策樹的輸出特別容易閱讀和解釋。決策樹的圖形表示並不依賴對統計學的高階理解。因此,決策樹及其表示可用於解釋、解釋和支援更複雜的分析結果。決策樹非常擅長尋找並突出顯示給定資料集的一些高級屬性。
需要最少的數據處理
可以在不完整的資料或包含異常值的資料上輕鬆建立決策樹。給定帶有有趣特徵的數據,如果向決策樹演算法提供未經預處理的數據,則它們往往不會像其他機器學習演算法那樣受到影響。
機器學習中決策樹的缺點
雖然決策樹有很多好處,但它們也有一些缺點:
容易過度擬合
決策樹很容易出現過度擬合,當模型學習訓練資料中的雜訊和細節時就會發生這種情況,從而降低其在新資料上的效能。例如,如果訓練資料不完整或稀疏,資料中的微小變化可能會產生顯著不同的樹狀結構。修剪或設定最大深度等先進技術可以改善樹木行為。在實踐中,決策樹通常需要使用新資訊進行更新,這可能會顯著改變其結構。
可擴展性差
除了過度擬合的傾向之外,決策樹也難以解決需要更多資料的更高階問題。與其他演算法相比,決策樹的訓練時間隨著資料量的增長而迅速增加。對於可能具有需要檢測的重要高階屬性的較大資料集,決策樹不太適合。
對於回歸或連續用例不太有效
決策樹不能很好地學習複雜的資料分佈。他們沿著易於理解但數學上簡單的線分割特徵空間。對於與異常值相關的複雜問題、迴歸和連續用例,這通常會導致效能比其他機器學習模型和技術差得多。