
機器學習中什麼是過度擬合?
已發表: 2024-10-15過度擬合是訓練機器學習 (ML) 模型時出現的常見問題。它可能會對模型超越訓練資料的泛化能力產生負面影響,從而導致在現實場景中的預測不準確。在本文中,我們將探討什麼是過度擬合、它是如何發生的、背後的常見原因以及檢測和預防它的有效方法。
目錄
- 什麼是過擬合?
- 過擬合是如何發生的
- 過擬合與欠擬合
- 是什麼導致過擬合?
- 如何檢測過度擬合
- 如何避免過度擬合
- 過度擬合的例子
什麼是過擬合?
過度擬合是指機器學習模型學習了訓練資料中的潛在模式和噪聲,從而變得對該特定資料集過於專業化。當模型應用於新的、未見過的資料時,過度關注訓練資料的細節會導致效能不佳,因為它無法概括超出其訓練資料的範圍。
過度擬合是如何發生的?
當模型從訓練資料中的特定細節和雜訊中學習過多時,就會發生過度擬合,使其對對泛化沒有意義的模式過於敏感。例如,考慮一個基於歷史評估來預測員工績效的模型。如果模型過度擬合,它可能會過度關注特定的、不可概括的細節,例如前經理的獨特評級風格或過去審核週期中的特定情況。該模型可能難以將其知識應用於新員工或建立評估標準,而不是學習有助於績效的更廣泛、有意義的因素(例如技能、經驗或專案成果)。當模型應用於與訓練集不同的資料時,這會導致預測不太準確。
過擬合與欠擬合
與過度擬合相反,當模型太簡單而無法捕捉資料中的潛在模式時,就會發生欠擬合。因此,它在訓練和新數據上的表現都很差,無法做出準確的預測。
為了可視化欠擬合和過度擬合之間的差異,想像一下我們正在嘗試根據一個人的壓力水平來預測運動表現。我們可以繪製數據並顯示嘗試預測這種關係的三個模型:

1欠擬合:在第一個範例中,模型使用直線進行預測,而實際資料則遵循曲線。此模型過於簡單,無法捕捉壓力水平和運動表現之間關係的複雜性。因此,即使對於訓練數據,預測也大多不準確。這是欠擬合的。
2最佳擬合:第二個範例顯示了達到適當平衡的模型。它捕獲了數據的潛在趨勢,但又不會使其過於複雜。該模型可以很好地推廣到新數據,因為它不會嘗試適應訓練數據中的每個微小變化,而只是適應核心模式。
3過度擬合:在最後一個範例中,模型使用高度複雜的波浪曲線來擬合訓練資料。雖然這條曲線對於訓練資料非常準確,但它也捕捉了不代表實際關係的隨機雜訊和異常值。該模型過度擬合,因為它對訓練資料進行瞭如此精細的調整,以至於可能對新的、未見過的資料做出糟糕的預測。
過度擬合的常見原因
現在我們知道什麼是過度擬合以及為什麼會發生過度擬合,讓我們更詳細地探討一些常見原因:
- 訓練資料不足
- 不準確、錯誤或不相關的數據
- 大重量
- 過度訓練
- 模型架構過於複雜
訓練資料不足
如果您的訓練資料集太小,它可能只代表模型在現實世界中會遇到的一些場景。在訓練過程中,模型可以很好地擬合資料。但是,一旦您在其他數據上進行測試,您可能會發現明顯的不準確之處。小數據集限制了模型泛化到未見過的情況的能力,使其容易過度擬合。
不準確、錯誤或不相關的數據
即使您的訓練資料集很大,它也可能包含錯誤。這些錯誤可能由多種來源引起,例如參與者在調查中提供虛假資訊或錯誤的感測器讀數。如果模型試圖從這些不準確性中學習,它將適應不反映真實潛在關係的模式,從而導致過度擬合。
大重量
在機器學習模型中,權重是表示在進行預測時分配給資料中特定特徵的重要性的數值。當權重變得不成比例地大時,模型可能會過度擬合,對某些特徵(包括資料中的雜訊)變得過於敏感。發生這種情況是因為模型過於依賴特定特徵,這損害了其泛化到新資料的能力。

過度訓練
在訓練過程中,演算法分批處理數據,計算每批的誤差,並調整模型的權重以提高其準確性。
盡可能長時間地繼續訓練是個好主意嗎?並不真地!對相同資料的長時間訓練可能會導致模型記住特定的資料點,限制其泛化到新的或未見過的資料的能力,這就是過度擬合的本質。這種類型的過度擬合可以透過使用提前停止技術或在訓練期間監控模型在驗證集上的表現來緩解。我們將在本文後面討論其工作原理。
模型架構過於複雜
機器學習模型的架構是指其層和神經元的結構以及它們如何互動以處理資訊。
更複雜的架構可以捕捉訓練資料中的詳細模式。然而,這種複雜性增加了過度擬合的可能性,因為模型也可能學習捕捉雜訊或不相關的細節,這些細節無助於對新資料的準確預測。簡化架構或使用正規化技術可以幫助降低過度擬合的風險。
如何檢測過度擬合
檢測過度擬合可能很棘手,因為即使發生了過度擬合,訓練期間一切似乎都進展順利。即使在過度擬合的情況下,損失(或錯誤)率(衡量模型錯誤頻率的指標)也將繼續下降。那麼,我們如何知道是否發生了過擬合呢?我們需要一個可靠的測試。
一種有效的方法是使用學習曲線,這是一種追蹤稱為損失的度量的圖表。損失代表模型所犯錯誤的大小。然而,我們不僅追蹤訓練資料的損失;還追蹤訓練資料的損失。我們還測量看不見的數據(稱為驗證數據)的損失。這就是為什麼學習曲線通常有兩條線:訓練損失和驗證損失。
如果訓練損失繼續按預期減少,但驗證損失增加,則表示過度擬合。換句話說,該模型對於訓練資料變得過於專業化,並且難以推廣到新的、看不見的資料。學習曲線可能看起來像這樣:
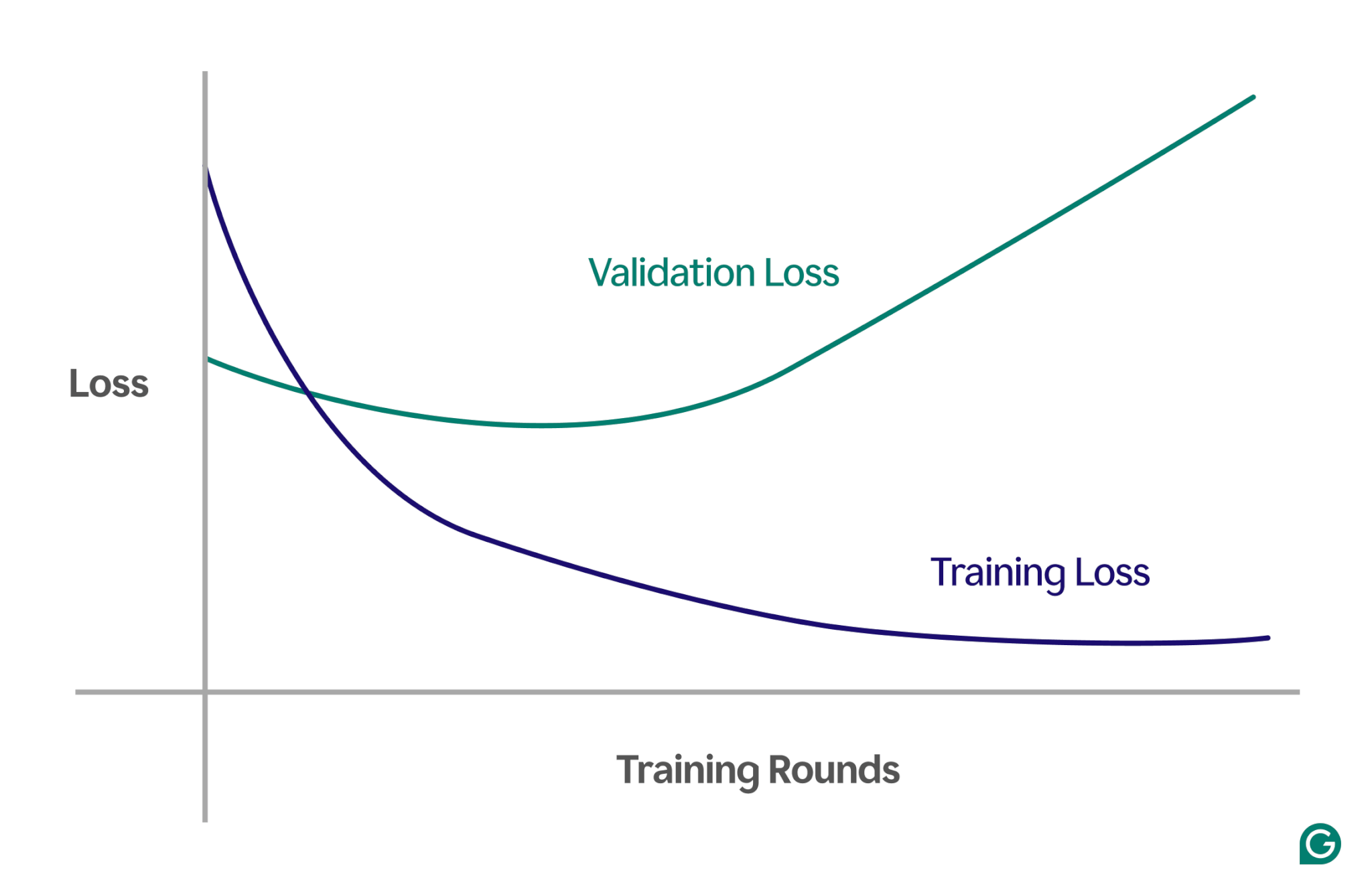
在這種情況下,雖然模型在訓練過程中有所改進,但它在未見過的資料上表現不佳。這可能意味著發生了過度擬合。
如何避免過度擬合
可以使用多種技術來解決過度擬合問題。以下是一些最常見的方法:
縮小模型尺寸
大多數模型架構可讓您透過變更層數、層大小和其他稱為超參數的參數來調整權重數量。如果模型的複雜性導致過度擬合,減少模型的大小會有所幫助。透過減少層數或神經元數量來簡化模型可以降低過度擬合的風險,因為模型記住訓練資料的機會會減少。
正規化模型
正則化涉及修改模型以阻止大權重。一種方法是調整損失函數,使其測量誤差並包含權重的大小。
透過正規化,訓練演算法可以最大限度地減少誤差和權重的大小,從而降低大權重的可能性,除非它們為模型提供了明顯的優勢。這有助於透過保持模型更加通用來防止過度擬合。
增加更多訓練數據
增加訓練資料集的大小也有助於防止過度擬合。資料越多,模型就不太可能受到資料集中的雜訊或不準確的影響。讓模型接觸更多不同的範例將使其不太傾向於記住單一數據點,而是學習更廣泛的模式。
應用降維
有時,資料可能包含相關特徵(或維度),這意味著多個特徵以某種方式相關。機器學習模型將維度視為獨立的,因此如果特徵相關,則模型可能會過於關注它們,從而導致過度擬合。
主成分分析 (PCA) 等統計技術可以減少這些相關性。 PCA 透過減少維數和消除相關性來簡化數據,從而降低過度擬合的可能性。透過關注最相關的特徵,模型能夠更好地泛化到新資料。
過度擬合的實際例子
為了更好地理解過度擬合,讓我們探討不同領域的一些實際範例,在這些範例中過度擬合可能會導致誤導性結果。
影像分類
圖像分類器旨在識別圖像中的對象,例如,圖片中是否包含鳥或狗。
其他細節可能與您試圖在這些圖片中偵測到的內容相關。例如,狗狗照片的背景可能經常有草,而鳥類照片的背景可能經常有天空或樹梢。
如果所有訓練圖像都具有這些一致的背景細節,機器學習模型可能會開始依賴背景來識別動物,而不是關注動物本身的實際特徵。因此,當要求模型對棲息在草坪上的鳥的圖像進行分類時,它可能會錯誤地將其分類為狗,因為它與背景資訊過度擬合。這是對訓練資料過度擬合的情況。
財務建模
假設您在業餘時間交易股票,並且您認為可以根據 Google 搜尋某些關鍵字的趨勢來預測價格走勢。您使用數千個單字的 Google 趨勢資料建立了機器學習模型。
由於單字太多,有些單字可能純粹是偶然地與您的股票價格顯示出相關性。該模型可能會過度擬合這些巧合的相關性,對未來數據做出糟糕的預測,因為這些詞彙不是股票價格的相關預測因子。
在建構金融應用模型時,了解資料關係的理論基礎非常重要。在沒有仔細選擇特徵的情況下將大型資料集輸入模型可能會增加過度擬合的風險,特別是當模型識別出訓練資料中純粹偶然存在的虛假相關性時。
運動迷信
儘管與機器學習並不嚴格相關,但體育迷信可以說明過度擬合的概念,特別是當結果與邏輯上與結果無關的數據相關聯時。
在 2008 年歐洲足球錦標賽和 2010 年 FIFA 世界盃期間,一隻名叫保羅的章魚被用來預測德國隊的比賽結果。 2008 年,保羅的 6 個預測中有 4 個是正確的,2010 年則有 7 個預測全部正確。
如果您只考慮保羅過去預測的“訓練資料”,那麼與保羅選擇一致的模型似乎可以很好地預測結果。然而,這個模型不能很好地推廣到未來的比賽,因為章魚的選擇是比賽結果的不可靠預測因素。