
機器學習中的隨機森林:它們是什麼以及它們的工作方式
已發表: 2025-02-03隨機森林是機器學習(ML)中一種強大而多功能的技術。本指南將幫助您了解隨機森林,它們的工作方式以及其應用,福利和挑戰。
目錄
- 什麼是隨機森林?
- 決策樹與隨機森林:有什麼區別?
- 隨機森林如何工作
- 隨機森林的實際應用
- 隨機森林的優勢
- 隨機森林的缺點
什麼是隨機森林?
隨機森林是一種使用多個決策樹來預測的機器學習算法。這是一種專為分類和回歸任務而設計的監督學習方法。通過將許多樹木的產出結合在一起,隨機森林提高了準確性,降低了過度擬合,並且與單個決策樹相比提供了更穩定的預測。
決策樹與隨機森林:有什麼區別?
儘管隨機森林建立在決策樹上,但兩種算法在結構和應用方面有顯著差異:
決策樹
決策樹由三個主要組成部分組成:根節點,決策節點(內部節點)和葉節點。與流程圖一樣,決策過程從根節點開始,根據條件流出決策節點,並以代表結果的葉節點結束。儘管決策樹易於解釋和概念化,但它們也容易過度擬合,尤其是使用複雜或嘈雜的數據集。
隨機森林
隨機森林是決策樹的合奏,結合了產量以改進預測。每棵樹都經過唯一的自舉樣品(用替換的原始數據集的隨機採樣子集)進行訓練,並使用每個節點處的特徵的隨機選擇子集評估決策拆分。這種稱為特徵包裝的方法引入了樹木之間的多樣性。通過匯總預測(使用對分類或回歸平均值的多數投票),蘭多森森林比合奏中的任何單個決策樹都會產生更準確和穩定的結果。
隨機森林如何工作
隨機森林通過組合多個決策樹來創建強大而準確的預測模型來運作。
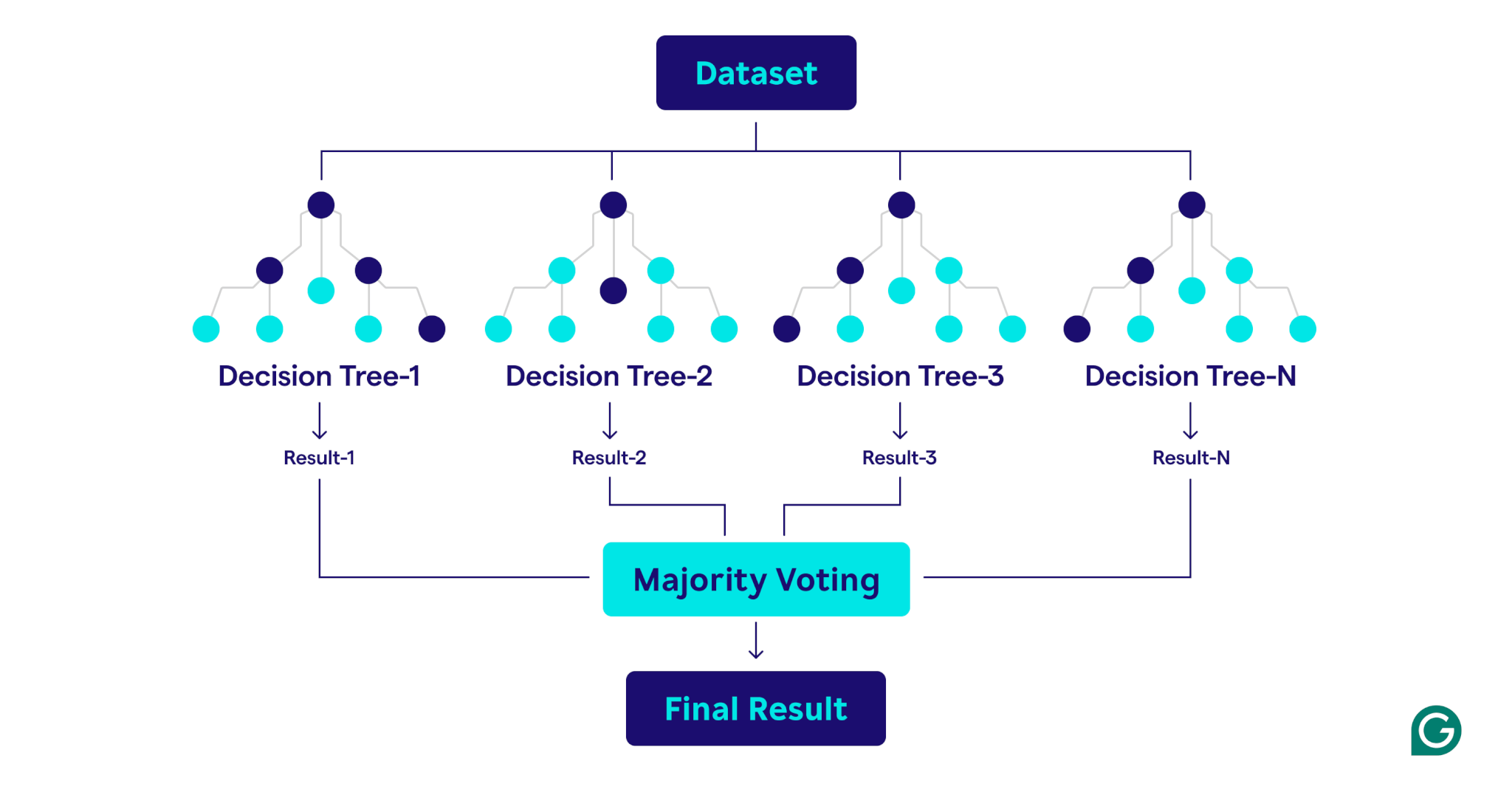
這是該過程的分步說明:
1。設置超參數
第一步是定義模型的超參數。其中包括:
- 樹木數:確定森林的大小
- 每棵樹的最大深度:控制每個決策樹可以生長的深度
- 每次分開考慮的功能數量:限制創建拆分時評估的功能數量
這些超參數允許微調模型的複雜性並優化特定數據集的性能。
2。引導抽樣
設置了超參數後,訓練過程始於自舉抽樣。這涉及:
- 隨機選擇原始數據集中的數據點以為每個決策樹創建培訓數據集(引導程序樣本)。
- 每個引導程序樣本通常約為原始數據集的大小的三分之二,有些數據點重複,而另一些數據點則排除在外。
- 其餘的三分之一的數據點(未包含在引導程序樣本中)被稱為外面(OOB)數據。
3。建造決策樹
隨機森林中的每個決策樹都使用唯一過程對其相應的自舉樣品進行了訓練:
- 功能包:在每次分開時,都會選擇一個隨機的特徵子集,從而確保樹木之間的多樣性。
- 節點拆分:子集中的最佳功能用於拆分節點:
- 對於分類任務,諸如Gini雜質之類的標準(對隨機選擇的元素的頻率度量,如果根據節點中的類標籤的分佈將其隨機標記,則將其分類不正確)。
- 對於回歸任務,諸如降低方差之類的技術(一種測量分裂節點的方法降低了目標值的方差,從而導致更精確的預測)評估拆分減少預測誤差的程度。
- 該樹遞歸生長,直到達到停止條件,例如最大深度或每個節點的最小數據點。
4。評估性能
在構造每棵樹時,使用OOB數據估算模型的性能:

- OOB誤差估計提供了對模型性能的公正度量,從而消除了對單獨的驗證數據集的需求。
- 通過匯總所有樹木的預測,與單個決策樹相比,隨機森林可提高準確性並減少過度擬合。
隨機森林的實際應用
像建造的決策樹一樣,隨機森林可以應用於各種各樣的部門(例如醫療保健和金融)的分類和回歸問題。
分類患者狀況
在醫療保健中,隨機森林用於根據病史,人口統計和測試結果等信息來對患者條件進行分類。例如,為了預測患者是否可能患有糖尿病等特定疾病,每個決策樹都會根據相關數據將患者歸類為處於風險中,並且隨機森林基於多數投票做出最終確定。這種方法意味著隨機森林特別適合醫療保健中發現的複雜,功能豐富的數據集。
預測貸款違約
銀行和主要金融機構廣泛使用隨機森林來確定貸款資格並更好地了解風險。該模型使用收入和信用評分等因素來確定風險。由於風險被衡量為連續數值,因此隨機森林執行回歸而不是分類。在略有不同的引導樣品樣本上訓練的每個決策樹都會輸出預測的風險評分。然後,隨機森林平均所有個體預測,從而產生了強大的整體風險估計。
預測客戶損失
在營銷中,隨機森林通常用於預測客戶停止使用產品或服務的可能性。這涉及分析客戶行為模式,例如購買頻率和與客戶服務的互動。通過識別這些模式,隨機森林可以對有離開風險的客戶進行分類。有了這些見解,公司可以採取積極主動的數據驅動步驟來保留客戶,例如提供忠誠度計劃或有針對性的促銷。
預測房地產價格
隨機森林可用於預測房地產價格,這是一項回歸任務。為了進行預測,隨機森林使用歷史數據,其中包括地理位置,平方英尺和該地區最近銷售的因素。隨機森林的平均過程比單個決策樹的價格預測更可靠,更穩定,這在高度波動的房地產市場中很有用。
隨機森林的優勢
隨機森林提供了許多優勢,包括準確性,魯棒性,多功能性以及估計特徵重要性的能力。
準確性和魯棒性
隨機森林比單個決策樹更準確,更健壯。這是通過結合在原始數據集的不同引導樣本上訓練的多個決策樹的輸出來實現的。由此產生的多樣性意味著,隨機森林比單個決策樹更容易擬合。這種合奏方法意味著即使在復雜的數據集中,隨機森林也擅長處理嘈雜的數據。
多功能性
就像建造的決策樹一樣,隨機森林的用途高度使用。他們可以處理回歸和分類任務,使其適用於廣泛的問題。隨機森林還可以與大型,功能豐富的數據集合作,並且可以處理數值和分類數據。
特徵重要性
隨機森林具有內置的能力來估計特定特徵的重要性。作為訓練過程的一部分,隨機森林輸出的分數可以測量如果去除特定功能,則模型的準確性會發生多大變化。通過平均每個特徵的分數,隨機森林可以提供可量化的特徵重要性度量。然後可以刪除不太重要的特徵,以創建更有效的樹木和森林。
隨機森林的缺點
儘管隨機森林提供了許多好處,但與單個決策樹相比,它們更難解釋,而訓練的成本更高,並且與其他模型相比,它們的輸出預測可能更慢。
複雜
儘管隨機的森林和決策樹有很多共同點,但隨機森林很難解釋和可視化。這種複雜性之所以出現,是因為隨機森林使用數百或數千個決策樹。當模型是一種要求時,隨機森林的“黑匣子”性質是一個嚴重的缺點。
計算成本
培訓數百或數千個決策樹需要比訓練單個決策樹更多的處理能力和記憶。當涉及大型數據集時,計算成本可能會更高。這項龐大的資源需求可能會導致更高的貨幣成本和更長的培訓時間。結果,在諸如Edge Computing之類的情況下,隨機森林可能不實用,因為計算能力和記憶都稀少。但是,隨機森林可以並行化,這可以幫助降低計算成本。
較慢的預測時間
隨機森林的預測過程涉及穿越森林中的每棵樹並彙總其輸出,這比使用單個模型固有的速度慢。與邏輯回歸或神經網絡(尤其是對於含有深樹木的大森林)相比,此過程可能導致預測時間較慢。對於時間本質上的用例(例如高頻交易或自動駕駛汽車),這種延遲可能會過時。